
Recurrent Neural Networks
Recurrent Neural Networks
Why Sequence Models?

레이블 데이터 X,Y를 사용하여 지도 학습으로 해결할 수 있다.
Notation

9단어의 sequence. Tx는 개수, Ty는 길이. (i): example, <t>: TIF element

단어 집합을 만든다. 사전에서 각각 빈도수로 가져온 단어 1만개. 단어 각각을 나타내는 one-hot 표현법.
단어 집합에 단어가 없을 때? => 단어 집합에 없는 단어를 표현하기 위한 UNK라는 단어를 만들기.
Recurrent Neural Network Model

input과 output이 동일한 길이가 아님. naive한 nn architecture는 텍스트의 서로 다른 위치에서 학습한 기능을 공유하지 않는다.

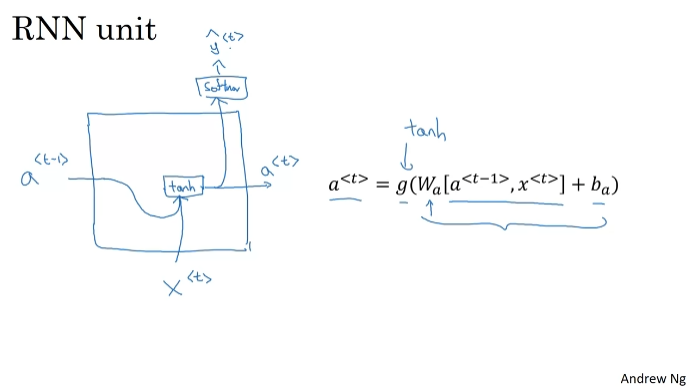
순환 신경망. activation value가 전달된다. 루프로 표현하기도 한다. y3를 예측할 때 x1,x2,x3의 값 모두가 전달된다. "teddy"라는 단어의 전 단어들도 전달된다.
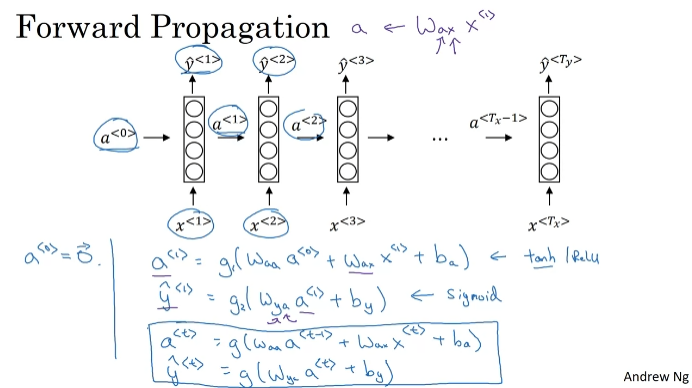
신경망 버전의 정리된 그림이다.
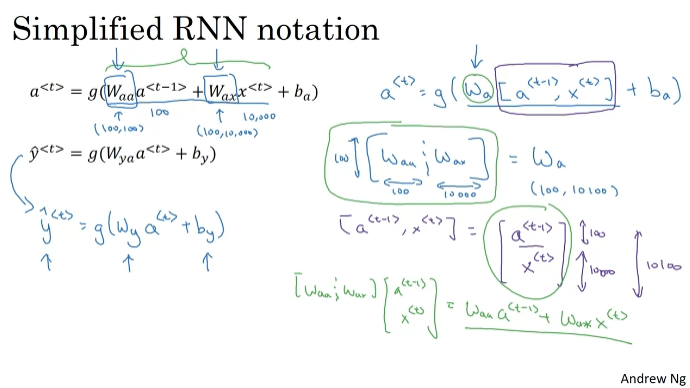
w_y, b_y를 사용하는 단순한 표기법으로 표기할 수 있다.
Backpropagation Through Time

시간 펼침 역전파 작동 방식.
Different Types of RNNs

Tx와 Ty가 길이가 꼭 같아야 하는 것은 아니다. 기본적인 RNN 아키텍처를 수정한다.

다대다 아키텍처. 다대일 아키텍처(많은 단어를 입력한 다음 숫자 출력. 리뷰 등). 완성도를 위한 일대일 아키텍처도 있다.
표준 신경망이 작을수록 약간의 입력값 x를 입력하면 약간의 출력값 y를 얻는다.
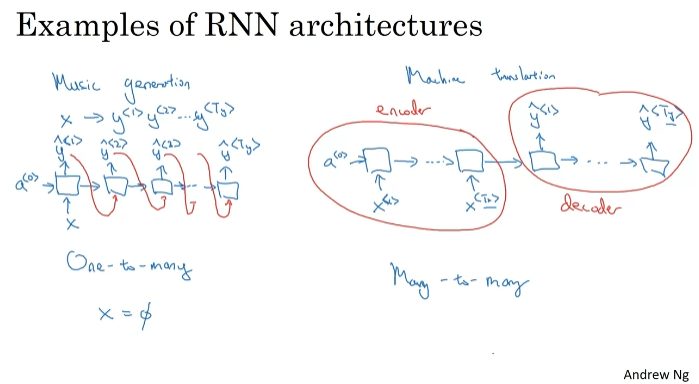
one-to-many(음악 생성). 합성된 출력값을 다음 레이어에도 전달한다.
many-to-many(입력과 출력 길이가 다름, 기계번역). 입력을 받아들이는 encoder와 출력을 하는 decoder가 있다.

요약. (one-to-one에는 RNN이 필요 없을 수 있다.)
Language Model and Sequence Generation

두 문장의 확률이 얼마인지 알려주는 language model을 사용한다. 두 번째 모델이 더 가능성이 있다.
모델의 확률을 알려준다.

RNN으로 language model을 만든다.
먼저, 문장을 토큰화해야한다.one-hot vector나 어휘의 색인으로 맵핑한다. EOS(end of sentence)라는 토큰을 더한다. 마침표는 넣거나 뺄 수 있다.
일부 단어가 어휘에 없다면? 미등록어를 뜻하는 UNK에 맵핑할 수 있다.

RNN 모델을 빌드한다. y^<1>은 소프트맥스에 따른 출력이고, 그 단어가 될 확률을 예측한다.
다음 단어를 예측하기도 한다.
Sampling a sequence from a trained RNN

sampling하기 위해서 무작위로 소프트맥스 분포에 따라 표본을 매긴다.(=y^<1>) 방금 샘플링한 값 (y^<1>) 을 입력으로 전달하고(one-hot 인코딩), y^<2>를 예측한다. EOS 토큰을 생성할 때까지 반복한다.UNK가 생성되는게 싫으면 알 수 없는 단어가 아닌 단어를 얻을 때까지 나머지 어휘와 리샘플링을 유지한다. 단어 수준의 샘플링

문자 수준 RNN. 교육 데이터의 개별 문자가 된다. Cat에서 C가 y1, a가 y2, t가 y3... 훨씬 더 긴 배열로 끝난다. 계산 비용이 많이 든다. 그래서 보통은 단어 수준으로 계산한다.

Vanishing Gradients with RNNs
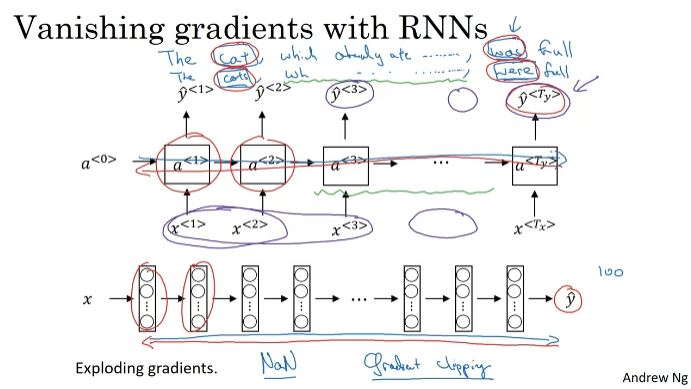
cat-was, cats-were. 기울기 소멸 문제로 신경망이 암기하기 어렵다. 단수임을 오랫동안 유지하기 위해야 하는데, 장거리 의존성에 그다지 뛰어나지 않다.
deep neural network에서 역전파를 할 때 기울기는 단순히 기하급수적으로 감소하지 않고 통과하는 레이어의 수에 따라 기하 급수적으로 증가할 수 있다. 이러한 기울기 폭주는 parameter가 폭주해 발견하기 쉽다. 벡터의 일부를 조정한다. gradient clipping.
하지만 기울기 소멸은 해결하기 어렵다.
Gated Recurrent Unit (GRU)

기울기 소멸 문제를 해결하기 위해 GRU 사용.
c라는 새로운 변수를 가지게 될 것이다. c,a라는 다른 기호를 같은 의미로 사용.

Long Short Term Memory (LSTM)


GRU보다 강력한 unit. update-forget-output.
Bidirectional RNN

시퀀스 한 지점의 전과 후 정보를 모두 사용한다. y3을 예측하는데 x1,x2,x3,x4 모두 사용.
Deep RNNs

시간에 맞춰 펼쳐짐.
Natural Language Processing & Word Embeddings
Introduction to Word Embeddings
Word Representation

one-hot으로 표현하는 것의 약점은 각 단어를 하나의 객체로 여겨 쉽게 일반화하지 않기 때문이다.

사전의 모든 단어를 이용하여 특징적인 표현을 배운다면 좋지 않을까? 각각의 특징과 값을 학습하기 위해서. 위 그림에서 단어들과 연관된 성별을 알고자 한다. 추가로, orange와 apple은 실제로 비슷한 값들을 가지고 있음을 확인할 수 있다.
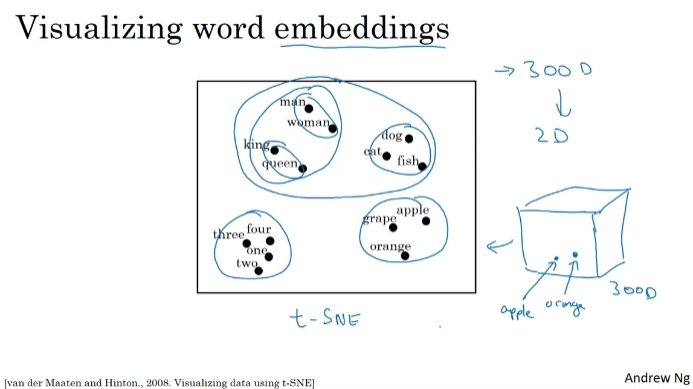
300차원 임베딩을 한다면, 300차원 데이터를 시각화할 수 있도록 2차원 공간에 임베딩 하는 것이다. t-SNE 알고리즘. 유사한 특징 벡터에 매핑.
Using Word Embeddings

사람의 이름일 때 1. sally johnson이 사람임을 알기 위한 한 가지 방법은 orange farmer가 사람임을 아는 것이다. 만약 orange former가 아니라 덜 평범한 단어라면? 단어 임베딩을 통해 매우 많은 단어들을 검토할 수 있다. 많게는 1천억개.
라벨이 없는 수많은 텍스트들을 살펴봄으로써 공짜로 더 많은 것을 다운로드 받을 수 있다. 이전학습 기능을 이용한다. 인터넷의 지식 사용.

양방향 RNN. 단어 임베딩으로 전달 배움 실행 가능. 온라인의 단어를 사용하고, 임베딩한 단어를 새로운 임무로 옮긴다.

인코딩은 임베딩과 유사하다. 얼굴인식은 신경 네트워크를 통해 새로운 그림에 대한 인코딩을 계산해 두 얼굴이 같은 얼굴인지 알아낸다. 단어들은 일정한 어휘(만 개의 단어)로 e1에서 벡터 e10000까지 배운다.
Properties of Word Embeddings
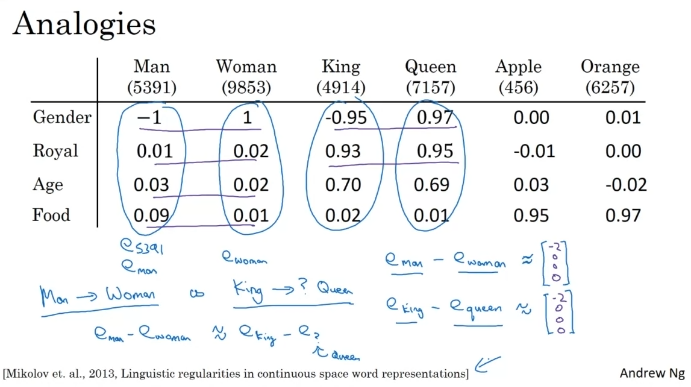
유추 문제에도 도움을 준다. 남자와 여자는 같은가? 뺄셈. man-woman이 king-queen과 비슷한 결과.

그래프가 가지는 의미. t-SNE는 2차원에 맵핑하는 복잡하고 비선형적인 맵핑이었다. 실제로 실제 300차원에서 평행사변형 관계가 더 명확하다. 비선형적인 t-SNE 때문에 유사성이 깨지기도 한다.

코사인 유사성.
Embedding matrix
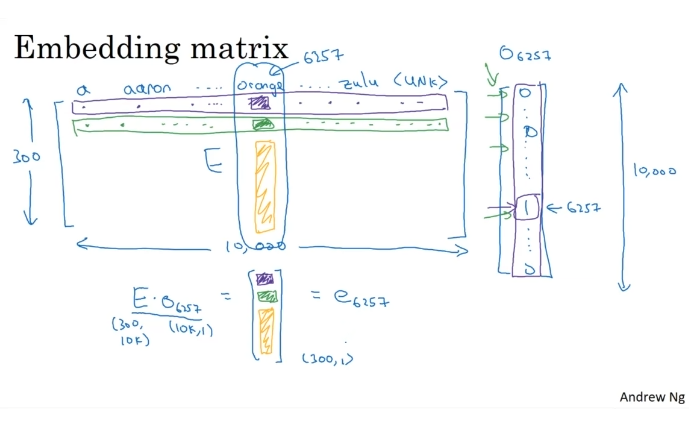
6257번 위치가 1이고 나머지는 0인 hot-vector. 보기 좋은 규모는 아니다.
임베딩 행렬E를 hot vecor o와 곱하면 300차원 벡터가 된다.
Larning Word Embeddings: Word2vec & GloVe
Larning Word Embeddings

각각 e는 300차원 벡터이다. 신경망에 채우고 softmax에 공급되어 발음에 따라 분류된다. 매개변수는 E.

왼쪽과 오른쪽 단어들을 보고 가운데 단어를 예측해야 한다. 혹은 바로 앞의 한 단어만. 혹은 가까운 한 단어만.(Skip-gram)
Word2Vec

Skip-gram : 건너뛰기 모델
무작위로 문맥이 될 단어를 골라낸다.

모델 구성. 네모는 작은 신경 네트워크이다. 기본적으로 만개를 올리고 아주 작은 최대 단위를 본다.
문맥 뒤에 무엇이 오는지 예측한다.

근접하게 나타나는 c,t를 고른다.
전체 어휘를 계산해야 해서 계산 속도가 문제가 된다. 해결1) 계층적 소프트맥스 모델을 사용한다. 로그로 확장. 트리는 완벽한 대칭이 아니다.
context c를 어떻게 결정하는가? 무작위로 가져오기. 자주 나타난다. a,the,.. 등 일반적인 단어와 일반적이지 않은 단어를 분류하는 것도 필요.
Negative Sampling

skip-gram보다 빠른 알고리즘. 1: positive, 2: negative. 문맥에 맞는 단어가 positive. 이후 지도 학습 문제를 만든다.

모델은 위와 같다. negative:positive = k:1. negative example 로지스틱 회귀에 이용. 모든 예제를 학습하는 대신 negative exapmle들을 학습한다.

negative example은 빈도에 따라 샘플링하거나(the,of,and 많이 나타날 위험 있음), 무작위로 찾는 방법도 있으나 가장 최적화된 위의 공식 P로 찾는다.
GloVe Word Vectors

GloVe는 단어를 나타내는 전역 벡터를 말한다. c,t를 명확하게 한다. c,t가 근접하게 나타나는지?

경사하강법으로 세타와 e에 대해서 i와 j가 10000일 때까지의 합을 최소화한다. 가중치 인자를 둔다.
제곱비용합수 최적화

다만 임베딩된 각각의 구성 요소가 해석이 가능한지 보장할 수 없다.
Applications Using Word Embeddings
Sentiment classification
감성 분류는 텍스트 일부를 보고 좋아하는지 여부를 판단하는 작업이다. 단어 임베딩을 이용하면 작은 규모의 레이블 훈련 세트만 있어도 좋은 감성 분류기를 만들 수 있다.

텍스트로 감성 분류. 방대한 레이블 세트가 없다면? 워드 임베딩 활용.

one-hot vector. 임베딩 행렬 E와 곱셈. 더 방대한 텍스트 말뭉치에서 학습 가능. 평균 계산. softmax 분류기(1~5까지의 확률)를 통해 y-hat 출력. 모든 단어의 확률 계산. 하지만 단어 순서 무시.

임베딩 벡터를 RNN 계산. many-to-one RNN 아키텍처. 새로운 단어에 대해서도 잘 계산할 수 있을 것이다.
Debiasing Word Embeddings

성별, 민족, 사회 지위 등에 대한 편향 없애기.

임베딩 벡터 빼서 평균을 내기. 계산 결과가 편향임. 편향 방향은 10차원 부분 공간, 비편향 방향은 299차원 부분 공간이다. 명확하지 않은 단어를 없애서 편향을 없앤다.명확한 단어들을 평준화한다.
Sequence Models & Attention Mechanism
Various Sequence To Sequence Architectures
Basic Models
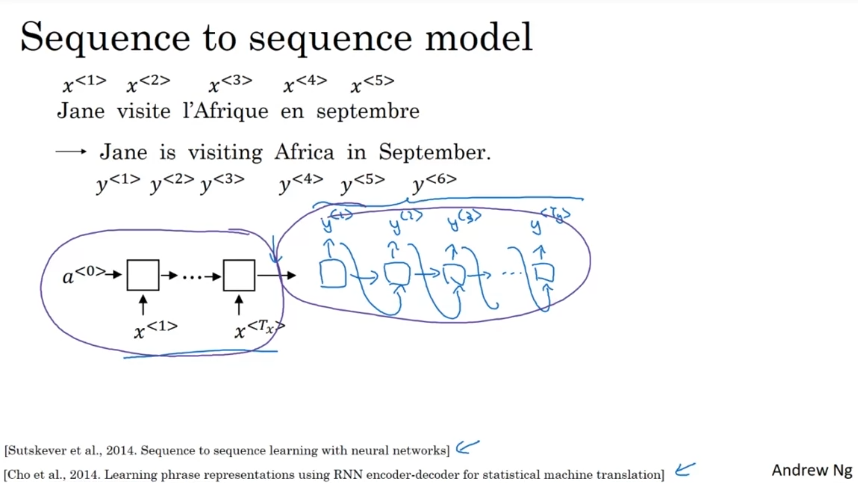
encoder network로 RNN을 수집한 후 decode network로 한 단어씩 번역을 output. 예시로 한 단어씩 넣어서 번역하는 것을 말할 수 있다.

자막을 내보내도록 하는 법? RNN 모델 사용. input vector, output set words.
Picking the Most Likely Sentence

조건부 언어 모델. 언어 모델은 한 모델의 확률을 추측한다.
기계번역 모델은 인코딩 디코딩이 나뉘어져 있다. 디코딩 모델이 언어 모델과 유사한 것을 확인할 수 있다. 대신 input이 문장이다. 영어 번역 출력을 모델링한다.

출력을 무작위로 샘플링하기는 싫을 것이다. 무작위로 샘플링하지 않고, 조건부 확률을 극대화하는 영어 문장 y를 찾는 것을 원한다. beam search.

greedy search를 사용하면 안되는 이유. 첫번째 단어로 가능성이 있는 두 번째 모델 선택... 효과가 없다. 한 번에 하나의 단어를 선택하는 것이 항상 최적인 것은 아니다.
Beam Search
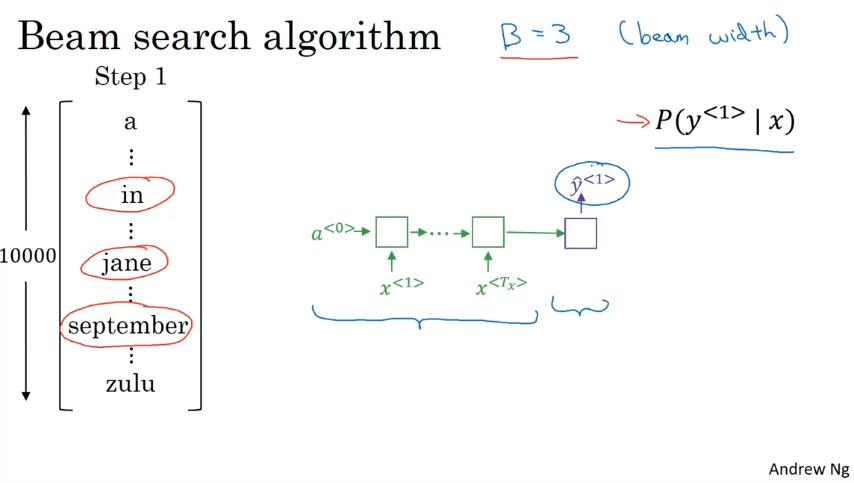
최상의 그럴듯한 문장 출력. 먼저, 첫 단어에 대한 확률 구하기. B라는 매개변수가 있다. B=3이면 세 가지 후보 고려.
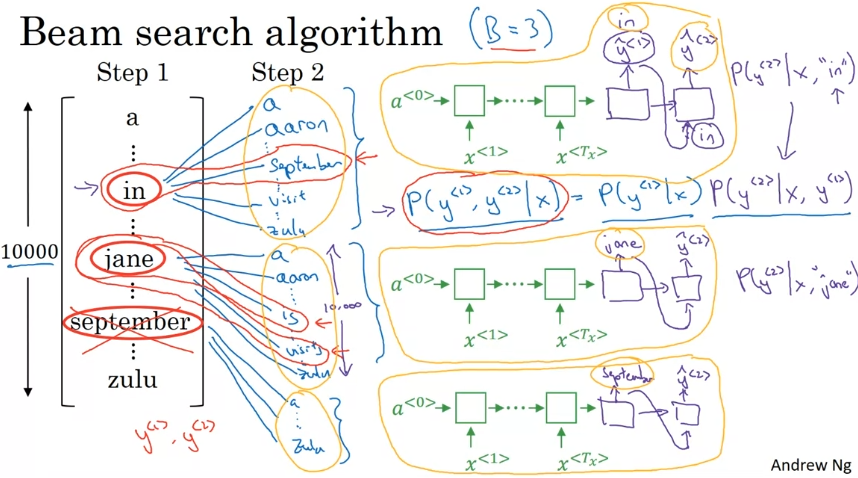

이후 두 번째 단어에 대한 확률 구하기. 첫 번째, 두 번째 단어 "쌍"에 대한 확률 구하기. 3가지 후보 선정.
Refinements to Beam Search

길이 정규화는 빔 서치 결과를 더욱 좋게 만들어준다. 빔 서치는 위 확률을 최대로 만들어 준다. 확률들은 전부 1보다 작은 수이다. 즉 곱한 결과는 매우 작다. 그래서 로그를 구하고 로그 합을 최대화한다. 언더플로우에 덜 취약하다.
문장이 매우 긴 경우 문장의 확률은 낮아지게 된다. 그래서 로그를 취해서 max를 구하는 대신 평균을 내서 긴 문장을 입력하는 패널티를 줄여준다. 가장 큰 값을 고른다.

B를 크게 설정하게 되면 여러 선택지를 시도해서 선택지가 느리고 메모리 요구량이 커진다.
B를 작게 하면 정확도가 낮아지고 빠르고 메모리 요구량이 작아진다.
생성 시스템에 따라 B의 너비는 다르다. 수천이어도 얻는 것이 크게 다르지 않기에 3~10이 권장된다. BFS, DFS와 다르게 훨씬 빠르지만 argmax를 찾는다는 보장이 없다.
Error Analysis in Beam Search

오류 분석하기. RNN과 Beam Search 알고리즘 중에 무엇이 문제일까. RNN은 인코더와 디코더를 의미한다.
모델을 이용하여 y*과 y^를 계산하고 어느것이 더 큰지 본다.

y*: RNN. y*가 더 큰 가치를 제공한다. 빔 서치가 잘못됐다.
y^: RNN 모델이 잘못됨.

오류 분석 프로세스.
Bleu Score (Optional)

여러가지의 좋은 정답이 있는 기계 번역 시스템 평가하는 방법
1) 기계학습 출력을 보고 reference에 나타나는지 보는 것이다. (7/7) 유용한 방법이 아니다.
단어 각각에 대해 최대 횟수만큼 크레딧을 부여한다. 수정된 정밀성 (2/7)
고립된 단어를 평가한 것이다.

2) bigrams, 단어의 쌍.

3) unigram=P1. n-gram = Pn. 비슷하거나 reference와 겹치는 정도를 추측할 수 있다. reference와 완전히 동일하면 1.0이다.

BP = brevity penalty. 너무 짧은 번역을 출력하는 번역 시스템에 불이익을 주는 조정 요소이다.
Attention Model Intuition
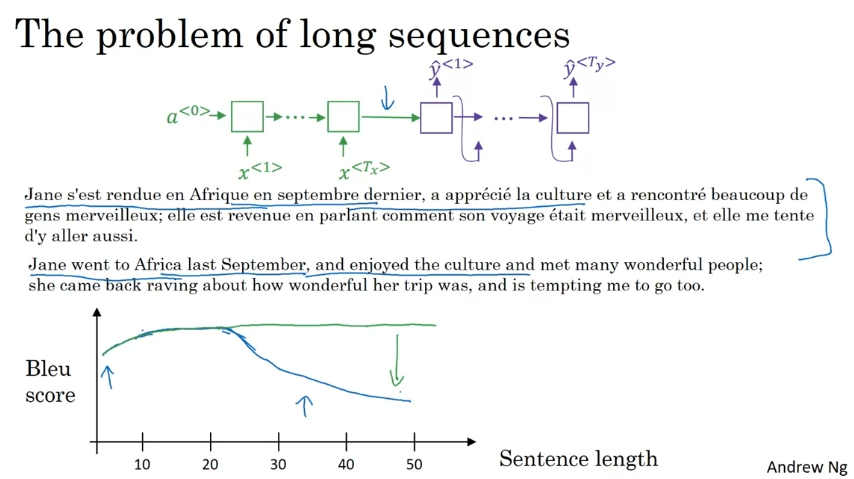
신경망을 외우기 어렵기 때문에 긴 문장이면 성능이 저하된다. 한 번에 문장의 일부만 보는 어텐션 모델을 사용하면 성능이 좋아보일 수 있다.

양방향 RNN으로 각 입력 단어에 대해 몇 가지 특징을 추출한다. EOS를 만나기 전까지 한 단어씩 만들어내는 RNN의 순방향 생성이며 알파<t,ti>라는 어텐션 가중치가 있다.
Attention Model
모든 단어의 특징 계산. LSTM, GRU가 사용되기도 한다.
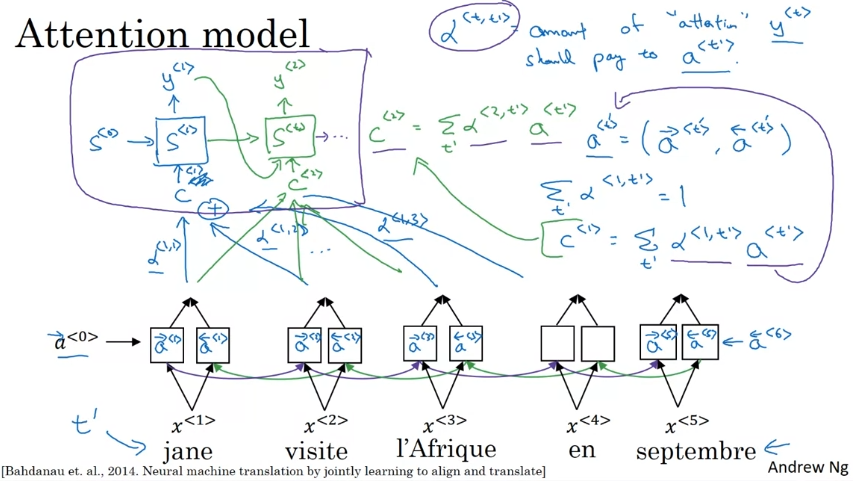
한 번에 한 단어씩 번역을 생성할 수 있음. context vectors도 생성할 수 있음.
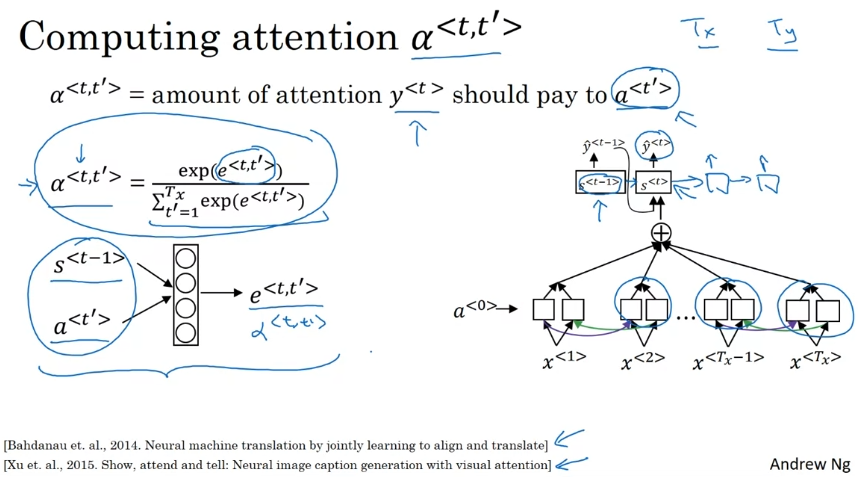
어텐션의 가중치 설정하는 방법. 소프트맥스 우선순위 활용. t' 활성화에 얼마나 주의를 기울일지 결정하고 싶다면 가장 신경 쓸 것은 이전 시간 단계의 은닉 상태 활성화이다. 어텐션 가중치 합이 1이 되게 한 다음 느리지만 한 번에 한 단어를 생성하도록 한다.

정규화. 어텐션 가중치의 시각화.
Speech Recognition - Audio Data
Speech Recognition
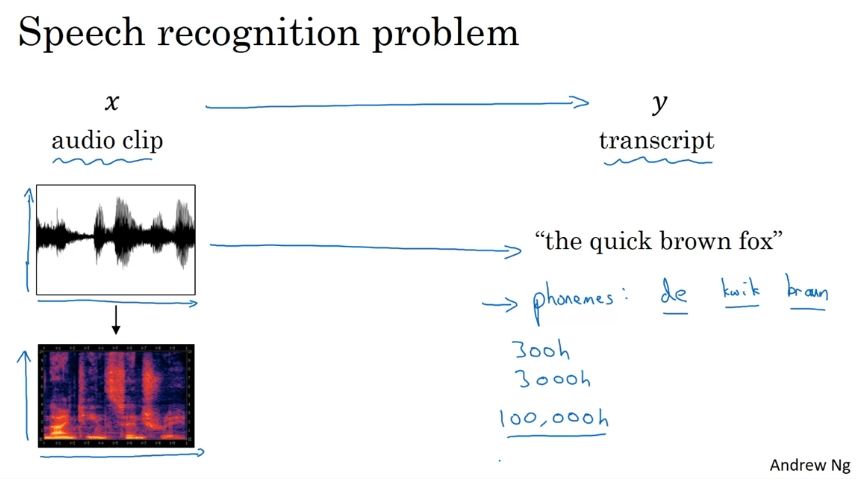
x축 시간, y축 공기압. 귀에는 주파수를 처리하는 과정이 있다.
음소 기반 인식 시스템이 있었다. 다대다 딥러닝으로 오디오 클립을 넣어 바로 글로 출력함.
큰 데이터세트를 만들어서 가능했다.

다양한 시간 단계의 오디오 인풋을 넣는다.

보통 입력이 더 크다.
Trigger Word Detection


활성화를 시키는 단어. 목표레이블을 1로 지정. 0이 많은 불균형 문제를 만들 수도 있다.
Transformer Network
Transformers
Transformer Network Motivation

점점 모델이 복잡해졌다. 그리고 sequence model로서 각 단위가 정보 플로우의 걸림돌이었다.

Attention과 CNN을 결합했다. 각 단어들에 대한 표현을 병렬로 계산함.
Self-Attention

각 단어별 어텐션 모델을 계산할 것. 사람들이 단어에 대해 어떻게 생각하고 있는지에 따라 다르게 표현을 찾음.
query,key,value가 어텐션 값을 계산하기 위한 핵심 input이다.
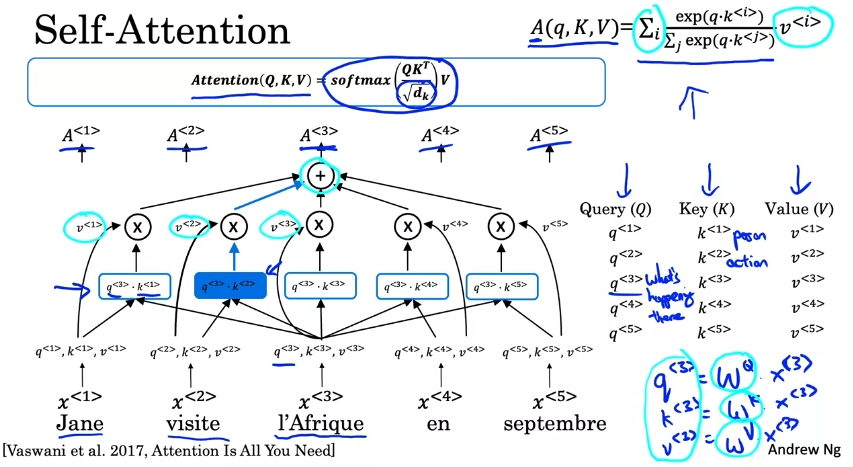
learned Matrix로 계산된다.
Multi-Head Attention

동일한 q,k,v 벡터 세트를 입력으로 사용한다. 어텐션을 계산할 때, what/when/who를 계산한다. 각각의 헤드가 다른 특징이다. 최종값은 헤드의 연속이다. 그리고 W matirx와 곱해진다.
Transformer Network

핵심사항.

추가사항. 입력 위치 인코딩. 계산 이외에도 residual connections(잔여 연결) 네트워크로 위치 인코딩을 전달할 수도 있다.

Add&Norm. 계산속도가 빨라진다.
'🚀 AI > Deep Learning' 카테고리의 다른 글
| Convolution Neural Networks (0) | 2023.10.12 |
|---|---|
| Structuring Machine Learning Projects (0) | 2023.09.29 |
| Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and Optimization (0) | 2023.09.24 |
| Neural Networks and Deep Learning (0) | 2023.09.10 |
| Neural Networks Basics (0) | 2023.09.06 |