
목차
-
3.1.1 파드가 필요한 이유
-
여러 프로세스를 실행하는 단일 컨테이너보다 다중 컨테이너가 나은 이유
-
3.1.2 파드 이해하기
-
같은 파드에서 컨테이너 부분 격리
-
컨테이너가 동일한 IP와 포트 공간을 공유하는 방법
-
파드 간 플랫 네트워크 소개
-
3.1.3 파드에서 컨테이너의 적절한 구성
-
다계층 애플리케이션을 여러 파드로 분할
-
개별 확장이 가능하도록 여러 파드로 분할
-
파드에서 여러 컨테이너를 사용하는 경우
-
파드에서 여러 컨테이너를 사용하는 경우 결정
-
3.2.1 기존 파드의 YAML 디스크립터 살펴보기
-
3.2.2 파드를 정의하는 간단한 YAML 정의 작성하기
-
컨테이너 포트 지정
-
3.2.3 kubectl create 명령으로 파드 만들기
-
실행 중인 파드의 전체 정의 가져오기
-
파드 목록에서 새로 생성된 파드 보기
-
3.2.4 애플리케이션 로그 보기
-
kubectl logs를 이용해 파드 로그 가져오기
-
컨테이너 이름을 지정해 다중 컨테이너에서 로그 가져오기
-
3.2.5 파드에 요청 보내기
-
로컬 네트워크 포트를 파드의 포트로 포워딩
-
포트 포워딩을 통해 파드 연결
-
3.3.1 레이블 소개
-
3.3.2 파드를 생성할 때 레이블 지정
-
3.3.3 기존 파드 레이블 수정
-
3.4.1 레이블 셀렉터를 사용해 파드 나열
-
3.4.2 레이블 셀렉터에서 여러 조건 사용
-
3.5.1 워커 노드 분류에 레이블 사용
-
3.5.2 특정 노드에 파드 스케줄링
-
3.5.3 하나의 특정 노드로 스케줄링
-
3.6.1 오브젝트의 어노테이션 조회
-
3.6.2 어노테이션 추가 및 수정
-
3.7.1 네임스페이스의 필요성
-
3.7.2 다른 네임 스페이스와 파드 살펴보기
-
3.7.3 네임스페이스 생성
-
3.7.4 다른 네임스페이스의 오브젝트 관리
-
3.7.5 네임스페이스가 제공하는 격리 이해
-
3.8.1 이름으로 파드 제거
-
3.8.2 레이블 셀렉터를 이용한 파드 삭제
-
3.8.3 네임스페이스를 삭제한 파드 제거
-
3.8.4 네임스페이스를 유지하면서 네임스페이스 안에 있는 모든 파드 삭제
-
3.8.5 네임스페이스에서 (거의) 모든 리소스 삭제
목표
- 파드의 생성, 실행, 정지
- 파드와 다른 리소스를 레이블로 조직화하기
- 특정 레이블을 가진 모든 파드에서 작업 수행
- 네임스페이스를 사용해 파드를 겹치지 않는 그룹으로 나누기
- 특정한 형식을 가진 워커 노드에 파드 배치
3.1 파드 소개
- 파드는 함께 배치된 컨테이너 그룹이며, 쿠버네티스의 기본 빌딩 블록이다.
- 컨테이너를 개별적으로 배포하기보다는 컨테이너를 가진 파드를 배포하고 운영한다.
- 여기에서 파드가 항상 두 개 이상의 컨테이너를 포함하는 것을 의미하는 것은 아니다. 일반적으로 파드는 하나의 컨테이너만 포함한다.
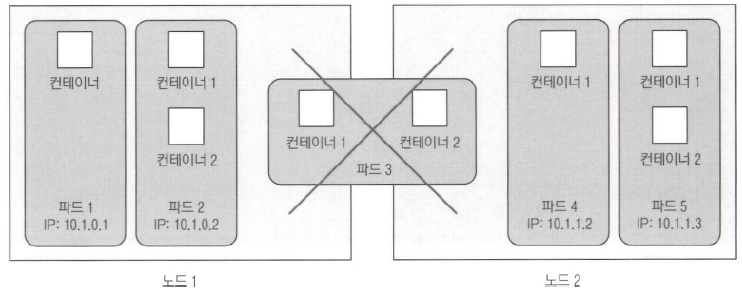
- 파드의 핵심 사항은 파드가 여러 컨테이너를 가지고 있을 경우에, 모든 컨테이너는 항상 하나의 워커 노드에서 실행되며 여러 워커 노드에 걸쳐 실행되지 않는다.
3.1.1 파드가 필요한 이유
여러 프로세스를 실행하는 단일 컨테이너보다 다중 컨테이너가 나은 이유
- 컨테이너는 단일 프로세스를 실행하는 것을 목적으로 설계했다.
- 단일 컨테이너에서 관련 없는 다른 프로세스를 실행하는 경우 모든 프로세스를 실행하고 로그를 관리하는 것은 모두 사용자 책임이다.
- 개별 프로세스가 실패하는 경우 자동으로 재시작하는 매커니즘 포함
- 모든 프로세스는 동일한 표준 출력으로 로그를 기록하기 때문에 어떤 프로세스가 남긴 로그인지 파악하는 것이 매우 어렵다.
- 단일 컨테이너에서 관련 없는 다른 프로세스를 실행하는 경우 모든 프로세스를 실행하고 로그를 관리하는 것은 모두 사용자 책임이다.
- 각 프로세스를 자체의 개별 컨테이너로 실행해야 한다. 이것이 도커와 쿠버네티스를 사용하는 방법이다.
3.1.2 파드 이해하기
- 여러 프로세스를 단일 컨테이너로 묶지 않기 때문에, 컨테이너를 함께 묶고 하나의 단위로 관리할 수 있는 또 다른 상위 구조가 필요하다. 이게 파드가 필요한 이유이다.
- 컨테이너 모음을 사용해 밀접하게 연관된 프로세스를 함께 실행하고 단일 컨테이너 안에서 모두 함께 실행되는 것처럼 거의 동일한 환경을 제공할 수 있으면서도 이들을 격리된 상태로 유지할 수 있다.
- 컨테이너가 제공하는 모든 기능을 활용하는 동시에 프로세스가 함께 실행되는 것처럼 보이게 할 수 있다.
같은 파드에서 컨테이너 부분 격리
- 컨테이너는 서로 완벽하게 격리돼 있다. (2장)
- 이제는 개별 컨테이너가 아닌 컨테이너 그룹을 분리하려 한다. 리소스를 공유하기 위해 완벽하게 격리되지 않도록 한다.
- 쿠버네티스는 파드 안에 있는 모든 컨테이너가 동일한 리눅스 네임스페이스를 공유하도록 도커를 설정한다.
- 파드의 모든 컨테이너는 동일한 네트워크 네임스페이스와 UTS 네임스페이스 안에서 실행되기 때문에, 모든 컨테이너는 같은 호스트 이름과 네트워크 인터페이스를 공유한다.
- 비슷하게 파드의 모든 컨테이너는 동일한 IPC 네임스페이스 아래에서 실행돼 IPC를 통해 서로 통신할 수 있다. 최신 쿠버네티스와 도커에서는 동일한 PID 네임스페이스를 공유할 수 있지만, 기본적으로 활성화되어 있지는 않다.
- 대부분의 컨테이너 파일시스템은 컨테이너 이미지에서 나오기 때문에, 기본적으로 파일시스템은 다른 컨테이너와 완전히 분리된다.
- 쿠버네티스의 볼륨 개념을 이용해 컨테이너가 파일 디렉터리를 공유하는 것이 가능하다. (6장)
컨테이너가 동일한 IP와 포트 공간을 공유하는 방법
- 파드 안의 컨테이너가 동일한 네트워크 네임스페이스에서 실행되며, 동일한 IP와 포트 공간을 공유한다.
- 같은 포트 번호 사용을 주의해야 한다.
- 파드 안에 있는 모든 컨테이너는 동일한 루프백 네트워크 인터페이스를 갖기 때문에, 컨테이너들이 로컬호스트를 통해 서로 통신할 수 있다.
파드 간 플랫 네트워크 소개
- 쿠버네티스 클러스터의 모든 파드는 하나의 플랫한 공유 네트워크 주소 공간에 상주하므로 모든 파드는 다른 파드의 IP 주소를 사용해 접근하는 것이 가능하다.
- 둘 사이에는 어떠한 NAT(Network Address Translation)도 존재하지 않는다.
- 두 파드가 서로 네트워크 패킷을 보내면, 상대방의 실제 IP 주소를 패킷 안에 있는 출발지 IP 주소에서 찾을 수 있다.즉, 각 파드는 라우팅 가능한 IP 주소를 얻고 모든 다른 파드는 해당 IP 주소를 통해 파드를 본다.
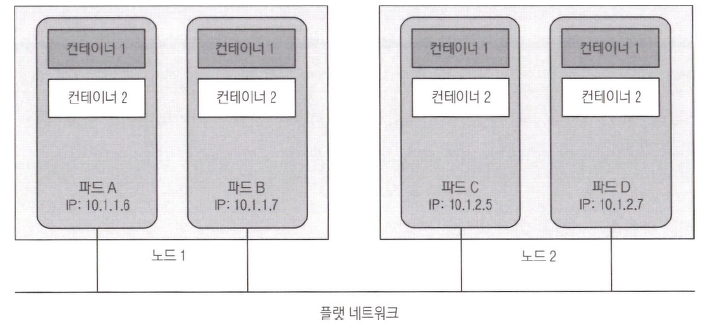
- 결론적으로 파드 사이에서 통신은 항상 단순하다.LAN에 있는 컴퓨터 간의 통신과 비슷하다. 각 파드는 고유 IP를 가지며 다른 파드에서 이를 통해 접속할 수 있다. 이는 일반적으로 물리 네트워크 위에 추가적인 소프트웨어 정의 네트워크 계층을 통해 달성된다.
- 이 절에서의 내용을 요약하면, 파드는 논리적인 호스트로서 컨테이너가 아닌 환경에서의 물리적 호스트 혹은 VM과 매우 유사하게 동작한다. 동일 파드에서 실행한 프로세스는 각 프로세스가 컨테이너 안에 캡슐화돼 있다는 점을 제외하면 동일하다.
3.1.3 파드에서 컨테이너의 적절한 구성
- 파드는 특정한 애플리케이션만을 호스팅한다.
- 파드는 상대적으로 가볍기 때문에, 모든 것을 파드 하나에 넣는 대신에 애플리케이션을 여러 파드로 구성하고, 각 파드에는 밀접하게 관련 있는 구성 요소나 프로세스만 포함해야 한다.
다계층 애플리케이션을 여러 파드로 분할
- 프론트엔드와 백엔드가 같은 파드에 있다면, 둘은 항상 같은 노드에서 실행된다.
- 만약 두 노드를 가진 쿠버네티스 클러스터가 있고 이 파드 하나만 있다면, 워커 노드 하나만 사용하고 두 번째 노드에서 이용할 수 있는 컴퓨팅 리소스(CPU와 메모리)를 활용하지 않고 버리게 된다.
- 이러한 경우에 파드를 두 개로 분리하면 활용도를 높일 수 있다.
개별 확장이 가능하도록 여러 파드로 분할
- 두 컨테이너를 하나의 파드에 넣지 말하야 하는 또 다른 이유는 스케일링 때문이다.
- 파드는 스케일링의 기본 단위다.
- 쿠버네티스는 개별 컨테이너를 수평으로 확장할 수 없다.
- 대신 전체 파드를 수평으로 확장한다.
- 만약 프론트엔드와 백엔드 컨테이너로 구성된 파드를 두 개로 늘리면, 결국 프론트엔드 컨테이너 두 개와 백엔드 컨테이너 두 개를 갖는다.
- 일반적으로 프론트엔드 구성 요소는 개별적으로 확장하는 경향이 있다.데이터베이스와 같은 백엔드는 상태를 갖지 않는 프론트엔드 웹 서버에 비해 확장하기 훨씬 어렵다.
- 컨테이너를 개별적으로 스케일링하는 것이 필요하다면 별도 파드에 배포해야 한다.
파드에서 여러 컨테이너를 사용하는 경우
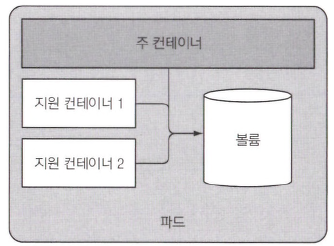
- 여러 컨테이너를 단일 파드에 넣는 주된 이유는, 아래 그림과 같이 애플리케이션이 하나의 주요 프로세스와 하나 이상의 보완 프로세스로 구성된 경우다.
- 예를 들어 파드 안에 주 컨테이너는 특정 디렉터리에서 파일을 제공하는 웹 서버일 수 있으며, 추가 컨테이너는 외부 소스에서 주기적으로 콘텐츠를 받아 웹서버의 디렉터리에 저장한다.
- 사이드카 컨테이너의 다른 예로는 로그 로테이터와 수집기, 데이터 프로세서, 통신 어댑터 등이 있다.
파드에서 여러 컨테이너를 사용하는 경우 결정
- 컨테이너를 파드로 묶어 그룹으로 만들 때는, 즉 두 개의 컨테이너를 단일 파드로 넣을지 아니면 두 개의 별도 파드에 넣을지를 결정하기 위해 다음과 같은 질문을 할 필요가 있다.
- 컨테이너를 함께 실행해야 하는가, 혹은 서로 다른 호스트에서 실행할 수 있는가?
- 여러 컨테이너가 모여 하나의 구성 요소를 나타내는가, 혹은 개별적인 구성 요소인가?
- 컨테이너가 함께, 혹은 개별적으로 스케일링돼야 하는가?
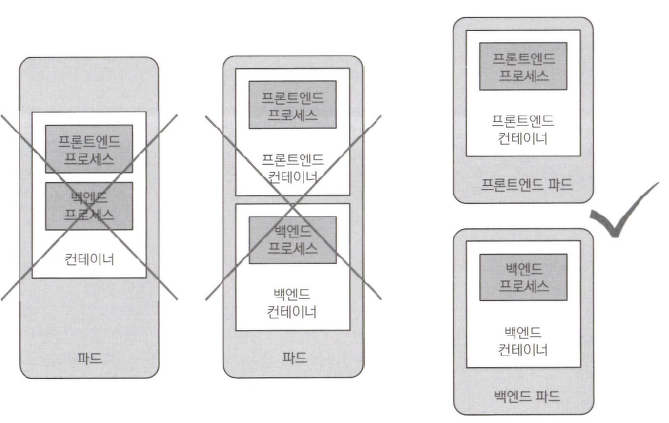
- 기본적으로 특정한 이유 때문에 컨테이너를 단일 파드로 구성하는 것을 요구하지 않는다면, 분리된 파드에서 컨테이너를 실행하는 것이 좋다.
컨테이너는 여러 프로세스를 실행시키지 말아야 한다. 파드는 동일한 머신에서 실행할 필요가 없다면 여러 컨테이너를 포함하지 말아야 한다. - 파드는 여러 컨테이너를 포함할 수 있지만, 지금은 단일 컨테이너 파드만을 다룬다.
3.2 YAML 또는 JSON 디스크립터로 파드 생성
- 파드를 포함한 다른 쿠버네티스 리소스는 일반적으로 쿠버네티스 REST API 엔드포인트에 JSON 혹은 YAML 매니페스트를 전송해 생성한다.
- kubectl run 명령처럼 다른 간단한 방법으로 리소스를 만들 수 있지만, 제한된 속성 집합만 설정할 수 있다.
- YAML 파일에 모든 쿠버네티스 오브젝트를 정의하면 버전 관리 시스템에 넣는 것이 가능해져, 그에 따른 모든 이점을 누릴 수 있다.
- 각 유형별 리소스의 모든 것을 구성하렴녀 쿠버네티스 API 오브젝트 정의를 알고 이해해야 한다.
- 오브젝트를 만들 때 https://kubernetes.io/docs/reference/의 쿠버네티스 API Reference 문서를 참고한다.
3.2.1 기존 파드의 YAML 디스크립터 살펴보기
- kubectl get 명령과 함께 -o yaml 옵션을 사용해 전체 YAML 정의를 볼 수 있다.
- 예제에서는 위에서부터 다음과 같은 내용을 포함한다.
- 이 YAML 디스크립터에서 사용한 쿠버네티스 API 버전
- 쿠버네티스 오브젝트/리소스 유형
- 파드 메타데이터 (이름, 레이블, 어노테이션 등)
- 파드 정의/내용 (파드 컨테이너 목록, 볼륨 등)
- 파드와 그 안의 여러 컨테이너의 상세한 상태)
파드를 정의하는 주요 부분
- 세 가지 주요 부분
- Metadata: 이름, 네임스페이스, 레이블 및 파드에 관한 기타 정보를 포함한다.
- Spec: 파드 컨테이너, 볼륨, 기타 데이터 등 파드 자체에 관한 실제 명세를 가진다.
- Status: 파드 상태, 각 컨테이너 설명과 상태, 파드 내부 IP, 기타 기본 정보 등 현재 실행 중인 파드에 관한 현재 정보를 포함한다.
- 중요한 부분과 사소한 부분을 구분할 줄 알아야 한다. 또한, 새로운 파드를 만들 때 작성하는 YAML 내용은 훨씬 짧다.
3.2.2 파드를 정의하는 간단한 YAML 정의 작성하기
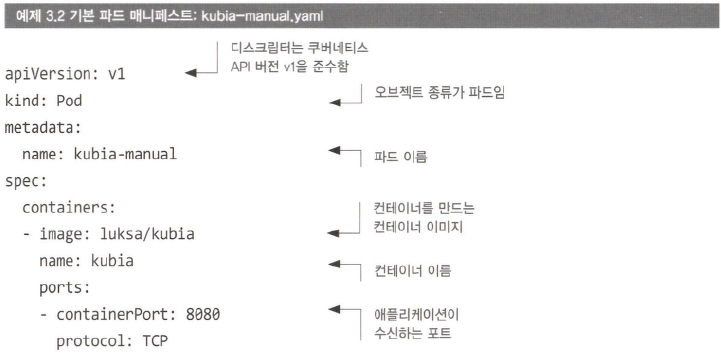
- 쿠버네티스 API v1 버전 준수
- 정의하는 리소스 유형은 파드이며 이름은 kubia-manual
- 파드는 luksa/kubia 이미지 기반 단일 컨테이너로 구성됨
- 컨테이너 이름을 지정하고 8080 포트에서 연결을 기다림
컨테이너 포트 지정
- 생략해도 다른 클라이언트에서 (8080) 포트를 통해 파드에 연결 여부에 영향을 미치지 않는다.
- 명시적으로 정의하면 포트에 이름을 지정해 편리하게 사용할 수 있다.
3.2.3 kubectl create 명령으로 파드 만들기
$ kubectl create -f kubia-manual.yaml
pod "kubia-manual" created실행 중인 파드의 전체 정의 가져오기
$ kubectl get po kubia-manual -o yaml #yaml 형식
$ kubectl get po kubia-manual -o json #json 형식파드 목록에서 새로 생성된 파드 보기
$ kubectl get pods # 파드 상태 조회3.2.4 애플리케이션 로그 보기
- 작은 Node.js 애플리케이션은 로그를 프로세스의 표준 출력에 기록한다.
- 컨테이너화된 애플리케이션은 로그를 파일에 쓰기보다는 표준 출력과 표준 에러에 로그를 남기는 것이 일반적이다.
- 컨테이너 런타임(여기서 도커)는 이러한 스트림을 파일로 전달하고, 다음 명령을 이용해 컨테이너 로그를 가져온다.
# 도커 로그 명령으로 로그를 확인
$ docker logs <container id>kubectl logs를 이용해 파드 로그 가져오기
$ kubectl logs kubia-manual컨테이너 이름을 지정해 다중 컨테이너에서 로그 가져오기
# -c 옵션을 통해 파드 속에 특정 컨테이너 로그 확인
$ kubectl logs kubia-manual -c kubia- 현존하는 파드의 컨테이너 로그만 가져올 수 있음.
- 파드 삭제 후에도 로그를 보기 위해서는 모든 로그를 중앙 저장소에 저장하는 클러스터 전체의 중앙 집중식 로깅을 설정해야 함. (17장)
3.2.5 파드에 요청 보내기
로컬 네트워크 포트를 파드의 포트로 포워딩
- 서비스를 거치지 않고 디버깅이나 다른 이유로 특정 파드와 대화하고 싶을 때 쿠버네티스는 해당 파드로 향하는 포트 포워딩을 구성해준다.
- 포트 포워딩 구성은 kubectl port-forward 명령으로 할 수 있다.
# 머신의 로컬 포트 8888을 kubia-manual 파드의 8080포트로 포워딩
$ kubectl port-forward kubia-manual 8888:8080포트 포워딩을 통해 파드 연결
- 다른 터미널에서 curl을 이용해 localhost:8888에서 실행되고 있는 kubectl port-forward 프록시를 통해 HTTP 요청을 해당 파드에 보낼 수 있다.
$ curl localhost:8888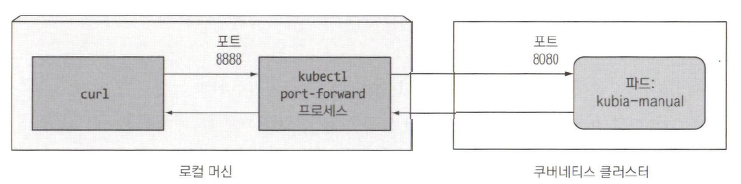
3.3 레이블을 이용한 파드 구성
- 파드의 수가 증가함에 따라 파드를 부분 집합으로 분류할 필요가 있다.
- 마이크로서비스 아키텍처의 경우 배포된 마이크로서비스의 수는 매우 쉽게 20개를 초과한다. 이러한 구성 요소는 복제돼 여러 버전 혹은 릴리즈가 동시에 실행된다.
- 이로 인해 시스템에 수백 개 파드가 생길 수 있다.
- 아래처럼 크고 이해하기 어려운 난장판이 된다.
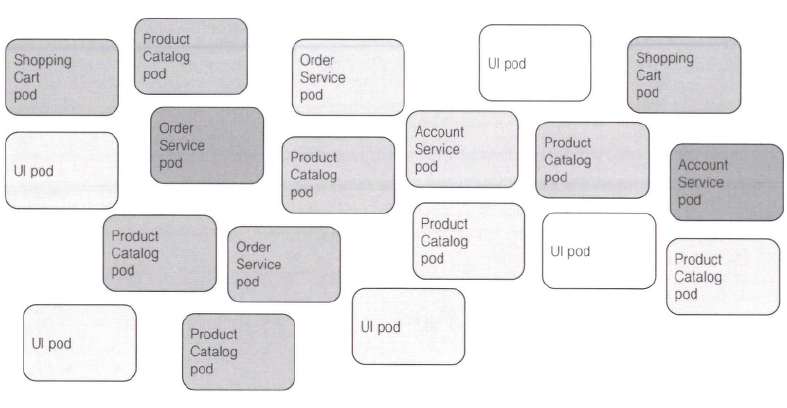
- 레이블(labels)를 통해 파드와 기타 다른 쿠버네티스 오브젝트의 조직화가 이뤄진다.
3.3.1 레이블 소개
- 레이블은 모든 다른 쿠버네티스 리소스를 조직화할 수 있는 기능이다.
- 레이블은 리소스에 첨부하는 키-값 쌍으로, 이 쌍은 레이블 셀력터를 사용해 리소스를 선택할 때 사용된다.
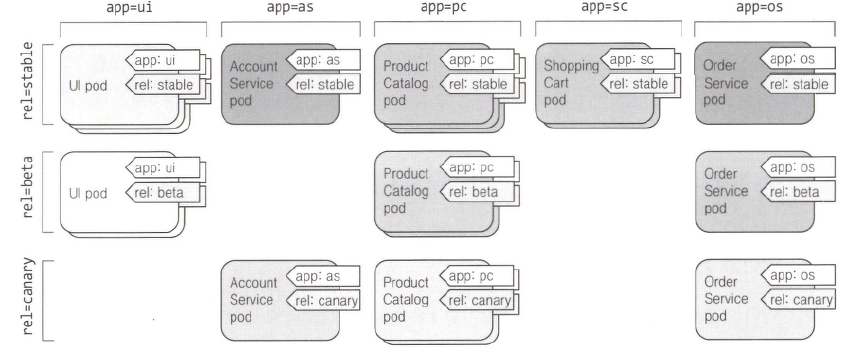
- 위 그림처럼 파드 레이블을 이용해 마이크로서비스 아키텍처 안에 파드를 조직화할 수 있다.
3.3.2 파드를 생성할 때 레이블 지정
- kubia-manual-with-labels.yaml 파일 생성
- labels: 추가
- 파드 생성
$ kubectl create -f kubia-manual-with-labels.yaml- 레이블 확인
$ kubectl get po --sho-labels3.3.3 기존 파드 레이블 수정
# 레이블 추가
$ kubectl label po kubia-manual creation_method=manual
# 레이블 변경
$ kubectl label po kubia-manual-v2 env=debug --overwrite
# 갱신된 레이블 확인
$ kubectl get po -L creation_method,env3.4 레이블 셀렉터를 이용한 파드 부분 집합 나열
- 레이블 셀렉터는 특정 레이블로 태그된 파드의 부분 집합을 선택해 원하는 작업을 수행한다.
- 다음 기준에 따라 리소스를 선택한다.
- 특정한 키를 포함하거나 포함하지 않는 레이블
- 특정한 키와 값을 가진 레이블
- 특정한 키를 갖고 있지만, 다른 값을 가진 레이블
3.4.1 레이블 셀렉터를 사용해 파드 나열
$ kubectl get po -l creation_method=manual
$ kubectl get po -l env
$ kubectl get po -l '!env'3.4.2 레이블 셀렉터에서 여러 조건 사용
- 셀렉터는 쉼표로 구분된 여러 기준을 포함하는 것도 가능하다.
- 리소스가 모든 기준을 만족해야 한다.
- 레이블 셀렉터는 파드 부분 집합에 작업을 수행할 때 유용하다.
3.5 레이블과 셀렉터를 이용해 파드 스케줄링 제한
- 지금까지 생성한 모든 파드는 워커 노드 전체에 걸쳐 무작위로 스케줄링됐다. 이것이 쿠버네티스에서의 적절한 동작 방식이다. 쿠버네티스는 모든 노드를 하나의 대규모 배포 플랫폼으로 노출하기 때문에, 파드가 어느 노드에 스케줄링됐느냐는 중요하지 않다.
- 각 파드는 요청한 만큼의 정확한 컴퓨팅 리소스(CPU, 메모리 등)를 할당받는다. 그리고 다른 파드에서 해당 파드로 접근하는 것은 파드가 스케줄링된 노드에 아무런 영향을 받지 않는다. 그래서 쿠버네티스에서 파드를 어디에 스케줄링할지 알려줄 필요는 없다.
- 하지만 하드웨어 인프라가 동일하지 않은 경우나 GPU 계산 파드 스케줄링 등에서 파드를 스케줄링 위치에 영향을 미치고 싶을 때가 있다.
- 쿠버네티스의 전체적인 아이디어는 그 위에 실행되는 애플리케이션으로부터 실제 인프라스트럭처를 숨기는 것에 있기에 파드가 어떤 노드에 스케줄링돼야 하는지 구체적으로 지정하고 싶지는 않을 것이다.
- 그래서 정확한 노드를 지정하는 대신 필요한 노드 요구 사항을 기술하고 쿠버네티스가 요구 사항을 만족하는 노드를 선택하도록 한다.
3.5.1 워커 노드 분류에 레이블 사용
- 모든 쿠버네티스 오브젝트에 레이블을 부착할 수 있다.
- 일반적으로 팀에서 새 노드를 클러스터에 추가할 때, 노드가 제공하는 하드웨어나 파드를 스케줄링할 때 유용하게 사용할 수 있는 기타 사항을 레이블로 지정해 노드를 분류한다.
$ kubectl label node gke-kubia-85f6-node-0rrx gpu=true
# gke-kubia-85f6-node-0rrx 노드에 gpu=true라는 레이블을 붙임
$ kubectl get nodes -l gpu=true
# gpu=true 레이블을 가진 노드를 나열3.5.2 특정 노드에 파드 스케줄링

3.5.3 하나의 특정 노드로 스케줄링
- 파드는 특정한 노드로 스케줄링하는 것도 가능하다
- 각 노드에는 키를 kubernetes.io/hostname으로 하고 값에는 호스트 이름이 설정된 고유한 레이블이 있기 때문이다.
- 그러나 그 특정 노드가 오프라인 상태인 경우 스케줄링 되지 않을 수 있다.
- 개별 노드로 생각해서는 안된다.
- 레이블 셀렉터를 통해 지정한 특정 기준을 만족하는 노드의 논리적인 그룹을 생각해야한다.
3.6 파드에 어노테이션 달기
- 어노테이션은 키-값 쌍으로 레이블과 거의 비슷하지만 식별 정보를 갖지 않는다.
- 어노테이션은 더 많은 정보를 보유할 수 있다.
- 이는 주로 tools에서 사용된다.
- 쿠버네티스에 새로운 기능을 추가할 때, 파드나 다른 API 오브젝트에 설명을 추가할 때 어노테이션이 유용하게 사용된다.
3.6.1 오브젝트의 어노테이션 조회
- kubectl describe 명령을 이용하거나 YAML 전체 내용을 요청해야 한다.
- 어노테이션에는 상대적으로 큰 데이터를 넣을 수 있다. JSON 사용도 가능하다.
3.6.2 어노테이션 추가 및 수정
$ kubectl annotate pod kubia-manual mycompony.com/someannotation="foo bar"
$ kubectl describe pod kubia-manual # 추가한 어노테이션 확인3.7 네임스페이스를 사용한 리소스 그룹화
- 오브젝트를 겹치지 않는 그룹으로 분할하고자 할 때는 오브젝트를 네임스페이스로 그룹화한다.
- 이는 프로세스를 격리하는데 사용하는 리눅스 네임스페이스가 아니고, 쿠버네티스 네임스페이스는 오브젝트 이름의 범위를 제공한다.
- 같은 리소스 이름을 다른 네임스페이스에 걸쳐 여러 번 사용할 수 있게 해준다.
3.7.1 네임스페이스의 필요성
- 여러 네임스페이스를 사용하면 많은 구성 요소를 가진 복잡한 시스템을 좀 더 작은 개별 그룹으로 분리할 수 있다.
- 또한 multi-tenant 환경처럼 리소스를 분리하는 데 사용된다.
- 리소스를 프로덕션, 개발, QA 환경, 혹은 원하는 방법으로 나누어 사용할 수 있다.
- 리소스 이름은 네임스페이스 안에서만 고유하면 된다.
3.7.2 다른 네임 스페이스와 파드 살펴보기
$ kubectl get ns
# 모든 네임스페이스 확인
$ kubectl get po --namespace kube-system
# kube-system 네임스페이스에 속해 있는 파드를 확인
# --namespace 대신 -n 옵션 사용 가능3.7.3 네임스페이스 생성
- yaml으로 생성
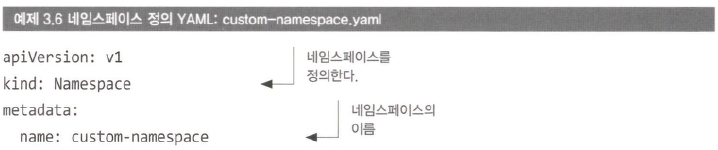
- kubectl create namespace 명령으로 생성
3.7.4 다른 네임스페이스의 오브젝트 관리
- 생성한 네임스페이스 안에 리소스를 만들기 위해서는 metadata 섹션에 namespace: custom -namespace 항목을 넣거나 kubectl create 명령을 사용할 때 네임스페이스를 지정한다.
$ kubectl create -f kubia-manual.yaml -n custom-namespace- 이제 동일한 이름을 가진 두 파드가 있다. 하나는 default 네임스페이스에 있고 나머지는 custom-namespace에 있다.
3.7.5 네임스페이스가 제공하는 격리 이해
- 네임스페이스를 사용하면 오브젝트를 별도 그룹으로 분리해 특정한 네임스페이스 안에 속한 리소스를 대상으로 작업할 수 있게 해주지만, 실행 중인 오브젝트에 대한 격리는 제공하지 않는다.
3.8 파드 중지와 제거
3.8.1 이름으로 파드 제거
$ kubectl delete po kubia-gpu- 파드를 삭제하면 쿠버네티스는 파드 안에 있는 모든 컨테이너를 종료한다.
- 쿠버네티스는 SIGTERM 신호를 프로세스에 보내고 지정된 시간 동안 기다린다. 시간 내에 종료되지 않으면 SIGKILL 신호를 통해 종료한다.
3.8.2 레이블 셀렉터를 이용한 파드 삭제
$ kubectl delete po -l creation_method=manual3.8.3 네임스페이스를 삭제한 파드 제거
$ kubectl delete ns custom-namespace
# 네임스페이스 전체 + 파드 삭제3.8.4 네임스페이스를 유지하면서 네임스페이스 안에 있는 모든 파드 삭제
$ kubectl delete po --all- 만약 레플리케이션컨트롤러에 의해 생성된 파드를 삭제했다면 즉시 새로운 파드를 생성한다. 파드를 삭제하기 위해서는 레플리케이션컨트롤러도 삭제해야 한다.
3.8.5 네임스페이스에서 (거의) 모든 리소스 삭제
- 레플리케이션컨트롤러, 파드, 생성한 모든 서비스 삭제
$ kubectl delete all --all3.9 요약
쿠버네티스의 중심이 되는 빌딩 블록에 대해 알아보았다. 배운 내용은 다음과 같다.
- 특정 컨테이너를 파드로 묶어야 하는지 여부를 결정하는 방법
- 파드는 여러 프로세스를 실행할 수 있으며 컨테이너가 아닌 세계의 물리적 호스트 와 비슷하다.
- YAML 또는 JSON 디스크립터를 작성해 파드를 작성하고 파드 정의와 상태를 확인할 수 있다.
- 레이블과 레이블 셀렉터를 사용해 파드를 조직하고 한 번에 여러 파드에서 작업을 쉽게 수행할 수 있다.
- 노드 레이블과 셀렉터를 사용해 특정 기능을 가진 노드에 파드를 스케줄링할 수 있다.
- 어노테이션을 사용하면 사람 또는 도구, 라이브러리에서 더 큰 데이터를 파드에 부착할 수 있다.
- 네임스페이스는 다른 팀들이 동일한 클러스터를 별도 클러스터를 사용하는 것처럼 이용할 수 있게 해준다.
- kubectl explain 명령으로 쿠버네티스 리소스 정보를 빠르게 찾을 수 있다.
'🍀 Cloud Architect > Kubernetes' 카테고리의 다른 글
| [Kubernetes in Action] Chapter 2. Understanding containers (0) | 2023.07.09 |
|---|---|
| [Kubernetes in Action] Chapter 1. Introducing Kubernetes (0) | 2023.07.09 |
목표
- 파드의 생성, 실행, 정지
- 파드와 다른 리소스를 레이블로 조직화하기
- 특정 레이블을 가진 모든 파드에서 작업 수행
- 네임스페이스를 사용해 파드를 겹치지 않는 그룹으로 나누기
- 특정한 형식을 가진 워커 노드에 파드 배치
3.1 파드 소개
- 파드는 함께 배치된 컨테이너 그룹이며, 쿠버네티스의 기본 빌딩 블록이다.
- 컨테이너를 개별적으로 배포하기보다는 컨테이너를 가진 파드를 배포하고 운영한다.
- 여기에서 파드가 항상 두 개 이상의 컨테이너를 포함하는 것을 의미하는 것은 아니다. 일반적으로 파드는 하나의 컨테이너만 포함한다.
- 파드의 핵심 사항은 파드가 여러 컨테이너를 가지고 있을 경우에, 모든 컨테이너는 항상 하나의 워커 노드에서 실행되며 여러 워커 노드에 걸쳐 실행되지 않는다.
3.1.1 파드가 필요한 이유
여러 프로세스를 실행하는 단일 컨테이너보다 다중 컨테이너가 나은 이유
- 컨테이너는 단일 프로세스를 실행하는 것을 목적으로 설계했다.
- 단일 컨테이너에서 관련 없는 다른 프로세스를 실행하는 경우 모든 프로세스를 실행하고 로그를 관리하는 것은 모두 사용자 책임이다.
- 개별 프로세스가 실패하는 경우 자동으로 재시작하는 매커니즘 포함
- 모든 프로세스는 동일한 표준 출력으로 로그를 기록하기 때문에 어떤 프로세스가 남긴 로그인지 파악하는 것이 매우 어렵다.
- 단일 컨테이너에서 관련 없는 다른 프로세스를 실행하는 경우 모든 프로세스를 실행하고 로그를 관리하는 것은 모두 사용자 책임이다.
- 각 프로세스를 자체의 개별 컨테이너로 실행해야 한다. 이것이 도커와 쿠버네티스를 사용하는 방법이다.
3.1.2 파드 이해하기
- 여러 프로세스를 단일 컨테이너로 묶지 않기 때문에, 컨테이너를 함께 묶고 하나의 단위로 관리할 수 있는 또 다른 상위 구조가 필요하다. 이게 파드가 필요한 이유이다.
- 컨테이너 모음을 사용해 밀접하게 연관된 프로세스를 함께 실행하고 단일 컨테이너 안에서 모두 함께 실행되는 것처럼 거의 동일한 환경을 제공할 수 있으면서도 이들을 격리된 상태로 유지할 수 있다.
- 컨테이너가 제공하는 모든 기능을 활용하는 동시에 프로세스가 함께 실행되는 것처럼 보이게 할 수 있다.
같은 파드에서 컨테이너 부분 격리
- 컨테이너는 서로 완벽하게 격리돼 있다. (2장)
- 이제는 개별 컨테이너가 아닌 컨테이너 그룹을 분리하려 한다. 리소스를 공유하기 위해 완벽하게 격리되지 않도록 한다.
- 쿠버네티스는 파드 안에 있는 모든 컨테이너가 동일한 리눅스 네임스페이스를 공유하도록 도커를 설정한다.
- 파드의 모든 컨테이너는 동일한 네트워크 네임스페이스와 UTS 네임스페이스 안에서 실행되기 때문에, 모든 컨테이너는 같은 호스트 이름과 네트워크 인터페이스를 공유한다.
- 비슷하게 파드의 모든 컨테이너는 동일한 IPC 네임스페이스 아래에서 실행돼 IPC를 통해 서로 통신할 수 있다. 최신 쿠버네티스와 도커에서는 동일한 PID 네임스페이스를 공유할 수 있지만, 기본적으로 활성화되어 있지는 않다.
- 대부분의 컨테이너 파일시스템은 컨테이너 이미지에서 나오기 때문에, 기본적으로 파일시스템은 다른 컨테이너와 완전히 분리된다.
- 쿠버네티스의 볼륨 개념을 이용해 컨테이너가 파일 디렉터리를 공유하는 것이 가능하다. (6장)
컨테이너가 동일한 IP와 포트 공간을 공유하는 방법
- 파드 안의 컨테이너가 동일한 네트워크 네임스페이스에서 실행되며, 동일한 IP와 포트 공간을 공유한다.
- 같은 포트 번호 사용을 주의해야 한다.
- 파드 안에 있는 모든 컨테이너는 동일한 루프백 네트워크 인터페이스를 갖기 때문에, 컨테이너들이 로컬호스트를 통해 서로 통신할 수 있다.
파드 간 플랫 네트워크 소개
- 쿠버네티스 클러스터의 모든 파드는 하나의 플랫한 공유 네트워크 주소 공간에 상주하므로 모든 파드는 다른 파드의 IP 주소를 사용해 접근하는 것이 가능하다.
- 둘 사이에는 어떠한 NAT(Network Address Translation)도 존재하지 않는다.
- 두 파드가 서로 네트워크 패킷을 보내면, 상대방의 실제 IP 주소를 패킷 안에 있는 출발지 IP 주소에서 찾을 수 있다.즉, 각 파드는 라우팅 가능한 IP 주소를 얻고 모든 다른 파드는 해당 IP 주소를 통해 파드를 본다.
- 결론적으로 파드 사이에서 통신은 항상 단순하다.LAN에 있는 컴퓨터 간의 통신과 비슷하다. 각 파드는 고유 IP를 가지며 다른 파드에서 이를 통해 접속할 수 있다. 이는 일반적으로 물리 네트워크 위에 추가적인 소프트웨어 정의 네트워크 계층을 통해 달성된다.
- 이 절에서의 내용을 요약하면, 파드는 논리적인 호스트로서 컨테이너가 아닌 환경에서의 물리적 호스트 혹은 VM과 매우 유사하게 동작한다. 동일 파드에서 실행한 프로세스는 각 프로세스가 컨테이너 안에 캡슐화돼 있다는 점을 제외하면 동일하다.
3.1.3 파드에서 컨테이너의 적절한 구성
- 파드는 특정한 애플리케이션만을 호스팅한다.
- 파드는 상대적으로 가볍기 때문에, 모든 것을 파드 하나에 넣는 대신에 애플리케이션을 여러 파드로 구성하고, 각 파드에는 밀접하게 관련 있는 구성 요소나 프로세스만 포함해야 한다.
다계층 애플리케이션을 여러 파드로 분할
- 프론트엔드와 백엔드가 같은 파드에 있다면, 둘은 항상 같은 노드에서 실행된다.
- 만약 두 노드를 가진 쿠버네티스 클러스터가 있고 이 파드 하나만 있다면, 워커 노드 하나만 사용하고 두 번째 노드에서 이용할 수 있는 컴퓨팅 리소스(CPU와 메모리)를 활용하지 않고 버리게 된다.
- 이러한 경우에 파드를 두 개로 분리하면 활용도를 높일 수 있다.
개별 확장이 가능하도록 여러 파드로 분할
- 두 컨테이너를 하나의 파드에 넣지 말하야 하는 또 다른 이유는 스케일링 때문이다.
- 파드는 스케일링의 기본 단위다.
- 쿠버네티스는 개별 컨테이너를 수평으로 확장할 수 없다.
- 대신 전체 파드를 수평으로 확장한다.
- 만약 프론트엔드와 백엔드 컨테이너로 구성된 파드를 두 개로 늘리면, 결국 프론트엔드 컨테이너 두 개와 백엔드 컨테이너 두 개를 갖는다.
- 일반적으로 프론트엔드 구성 요소는 개별적으로 확장하는 경향이 있다.데이터베이스와 같은 백엔드는 상태를 갖지 않는 프론트엔드 웹 서버에 비해 확장하기 훨씬 어렵다.
- 컨테이너를 개별적으로 스케일링하는 것이 필요하다면 별도 파드에 배포해야 한다.
파드에서 여러 컨테이너를 사용하는 경우
- 여러 컨테이너를 단일 파드에 넣는 주된 이유는, 아래 그림과 같이 애플리케이션이 하나의 주요 프로세스와 하나 이상의 보완 프로세스로 구성된 경우다.
- 예를 들어 파드 안에 주 컨테이너는 특정 디렉터리에서 파일을 제공하는 웹 서버일 수 있으며, 추가 컨테이너는 외부 소스에서 주기적으로 콘텐츠를 받아 웹서버의 디렉터리에 저장한다.
- 사이드카 컨테이너의 다른 예로는 로그 로테이터와 수집기, 데이터 프로세서, 통신 어댑터 등이 있다.
파드에서 여러 컨테이너를 사용하는 경우 결정
- 컨테이너를 파드로 묶어 그룹으로 만들 때는, 즉 두 개의 컨테이너를 단일 파드로 넣을지 아니면 두 개의 별도 파드에 넣을지를 결정하기 위해 다음과 같은 질문을 할 필요가 있다.
- 컨테이너를 함께 실행해야 하는가, 혹은 서로 다른 호스트에서 실행할 수 있는가?
- 여러 컨테이너가 모여 하나의 구성 요소를 나타내는가, 혹은 개별적인 구성 요소인가?
- 컨테이너가 함께, 혹은 개별적으로 스케일링돼야 하는가?
- 기본적으로 특정한 이유 때문에 컨테이너를 단일 파드로 구성하는 것을 요구하지 않는다면, 분리된 파드에서 컨테이너를 실행하는 것이 좋다.
컨테이너는 여러 프로세스를 실행시키지 말아야 한다. 파드는 동일한 머신에서 실행할 필요가 없다면 여러 컨테이너를 포함하지 말아야 한다. - 파드는 여러 컨테이너를 포함할 수 있지만, 지금은 단일 컨테이너 파드만을 다룬다.
3.2 YAML 또는 JSON 디스크립터로 파드 생성
- 파드를 포함한 다른 쿠버네티스 리소스는 일반적으로 쿠버네티스 REST API 엔드포인트에 JSON 혹은 YAML 매니페스트를 전송해 생성한다.
- kubectl run 명령처럼 다른 간단한 방법으로 리소스를 만들 수 있지만, 제한된 속성 집합만 설정할 수 있다.
- YAML 파일에 모든 쿠버네티스 오브젝트를 정의하면 버전 관리 시스템에 넣는 것이 가능해져, 그에 따른 모든 이점을 누릴 수 있다.
- 각 유형별 리소스의 모든 것을 구성하렴녀 쿠버네티스 API 오브젝트 정의를 알고 이해해야 한다.
- 오브젝트를 만들 때 https://kubernetes.io/docs/reference/의 쿠버네티스 API Reference 문서를 참고한다.
3.2.1 기존 파드의 YAML 디스크립터 살펴보기
- kubectl get 명령과 함께 -o yaml 옵션을 사용해 전체 YAML 정의를 볼 수 있다.
- 예제에서는 위에서부터 다음과 같은 내용을 포함한다.
- 이 YAML 디스크립터에서 사용한 쿠버네티스 API 버전
- 쿠버네티스 오브젝트/리소스 유형
- 파드 메타데이터 (이름, 레이블, 어노테이션 등)
- 파드 정의/내용 (파드 컨테이너 목록, 볼륨 등)
- 파드와 그 안의 여러 컨테이너의 상세한 상태)
파드를 정의하는 주요 부분
- 세 가지 주요 부분
- Metadata: 이름, 네임스페이스, 레이블 및 파드에 관한 기타 정보를 포함한다.
- Spec: 파드 컨테이너, 볼륨, 기타 데이터 등 파드 자체에 관한 실제 명세를 가진다.
- Status: 파드 상태, 각 컨테이너 설명과 상태, 파드 내부 IP, 기타 기본 정보 등 현재 실행 중인 파드에 관한 현재 정보를 포함한다.
- 중요한 부분과 사소한 부분을 구분할 줄 알아야 한다. 또한, 새로운 파드를 만들 때 작성하는 YAML 내용은 훨씬 짧다.
3.2.2 파드를 정의하는 간단한 YAML 정의 작성하기
- 쿠버네티스 API v1 버전 준수
- 정의하는 리소스 유형은 파드이며 이름은 kubia-manual
- 파드는 luksa/kubia 이미지 기반 단일 컨테이너로 구성됨
- 컨테이너 이름을 지정하고 8080 포트에서 연결을 기다림
컨테이너 포트 지정
- 생략해도 다른 클라이언트에서 (8080) 포트를 통해 파드에 연결 여부에 영향을 미치지 않는다.
- 명시적으로 정의하면 포트에 이름을 지정해 편리하게 사용할 수 있다.
3.2.3 kubectl create 명령으로 파드 만들기
$ kubectl create -f kubia-manual.yaml
pod "kubia-manual" created실행 중인 파드의 전체 정의 가져오기
$ kubectl get po kubia-manual -o yaml #yaml 형식
$ kubectl get po kubia-manual -o json #json 형식파드 목록에서 새로 생성된 파드 보기
$ kubectl get pods # 파드 상태 조회3.2.4 애플리케이션 로그 보기
- 작은 Node.js 애플리케이션은 로그를 프로세스의 표준 출력에 기록한다.
- 컨테이너화된 애플리케이션은 로그를 파일에 쓰기보다는 표준 출력과 표준 에러에 로그를 남기는 것이 일반적이다.
- 컨테이너 런타임(여기서 도커)는 이러한 스트림을 파일로 전달하고, 다음 명령을 이용해 컨테이너 로그를 가져온다.
# 도커 로그 명령으로 로그를 확인
$ docker logs <container id>kubectl logs를 이용해 파드 로그 가져오기
$ kubectl logs kubia-manual컨테이너 이름을 지정해 다중 컨테이너에서 로그 가져오기
# -c 옵션을 통해 파드 속에 특정 컨테이너 로그 확인
$ kubectl logs kubia-manual -c kubia- 현존하는 파드의 컨테이너 로그만 가져올 수 있음.
- 파드 삭제 후에도 로그를 보기 위해서는 모든 로그를 중앙 저장소에 저장하는 클러스터 전체의 중앙 집중식 로깅을 설정해야 함. (17장)
3.2.5 파드에 요청 보내기
로컬 네트워크 포트를 파드의 포트로 포워딩
- 서비스를 거치지 않고 디버깅이나 다른 이유로 특정 파드와 대화하고 싶을 때 쿠버네티스는 해당 파드로 향하는 포트 포워딩을 구성해준다.
- 포트 포워딩 구성은 kubectl port-forward 명령으로 할 수 있다.
# 머신의 로컬 포트 8888을 kubia-manual 파드의 8080포트로 포워딩
$ kubectl port-forward kubia-manual 8888:8080포트 포워딩을 통해 파드 연결
- 다른 터미널에서 curl을 이용해 localhost:8888에서 실행되고 있는 kubectl port-forward 프록시를 통해 HTTP 요청을 해당 파드에 보낼 수 있다.
$ curl localhost:88883.3 레이블을 이용한 파드 구성
- 파드의 수가 증가함에 따라 파드를 부분 집합으로 분류할 필요가 있다.
- 마이크로서비스 아키텍처의 경우 배포된 마이크로서비스의 수는 매우 쉽게 20개를 초과한다. 이러한 구성 요소는 복제돼 여러 버전 혹은 릴리즈가 동시에 실행된다.
- 이로 인해 시스템에 수백 개 파드가 생길 수 있다.
- 아래처럼 크고 이해하기 어려운 난장판이 된다.
- 레이블(labels)를 통해 파드와 기타 다른 쿠버네티스 오브젝트의 조직화가 이뤄진다.
3.3.1 레이블 소개
- 레이블은 모든 다른 쿠버네티스 리소스를 조직화할 수 있는 기능이다.
- 레이블은 리소스에 첨부하는 키-값 쌍으로, 이 쌍은 레이블 셀력터를 사용해 리소스를 선택할 때 사용된다.
- 위 그림처럼 파드 레이블을 이용해 마이크로서비스 아키텍처 안에 파드를 조직화할 수 있다.
3.3.2 파드를 생성할 때 레이블 지정
- kubia-manual-with-labels.yaml 파일 생성
- labels: 추가
- 파드 생성
$ kubectl create -f kubia-manual-with-labels.yaml- 레이블 확인
$ kubectl get po --sho-labels3.3.3 기존 파드 레이블 수정
# 레이블 추가
$ kubectl label po kubia-manual creation_method=manual
# 레이블 변경
$ kubectl label po kubia-manual-v2 env=debug --overwrite
# 갱신된 레이블 확인
$ kubectl get po -L creation_method,env3.4 레이블 셀렉터를 이용한 파드 부분 집합 나열
- 레이블 셀렉터는 특정 레이블로 태그된 파드의 부분 집합을 선택해 원하는 작업을 수행한다.
- 다음 기준에 따라 리소스를 선택한다.
- 특정한 키를 포함하거나 포함하지 않는 레이블
- 특정한 키와 값을 가진 레이블
- 특정한 키를 갖고 있지만, 다른 값을 가진 레이블
3.4.1 레이블 셀렉터를 사용해 파드 나열
$ kubectl get po -l creation_method=manual
$ kubectl get po -l env
$ kubectl get po -l '!env'3.4.2 레이블 셀렉터에서 여러 조건 사용
- 셀렉터는 쉼표로 구분된 여러 기준을 포함하는 것도 가능하다.
- 리소스가 모든 기준을 만족해야 한다.
- 레이블 셀렉터는 파드 부분 집합에 작업을 수행할 때 유용하다.
3.5 레이블과 셀렉터를 이용해 파드 스케줄링 제한
- 지금까지 생성한 모든 파드는 워커 노드 전체에 걸쳐 무작위로 스케줄링됐다. 이것이 쿠버네티스에서의 적절한 동작 방식이다. 쿠버네티스는 모든 노드를 하나의 대규모 배포 플랫폼으로 노출하기 때문에, 파드가 어느 노드에 스케줄링됐느냐는 중요하지 않다.
- 각 파드는 요청한 만큼의 정확한 컴퓨팅 리소스(CPU, 메모리 등)를 할당받는다. 그리고 다른 파드에서 해당 파드로 접근하는 것은 파드가 스케줄링된 노드에 아무런 영향을 받지 않는다. 그래서 쿠버네티스에서 파드를 어디에 스케줄링할지 알려줄 필요는 없다.
- 하지만 하드웨어 인프라가 동일하지 않은 경우나 GPU 계산 파드 스케줄링 등에서 파드를 스케줄링 위치에 영향을 미치고 싶을 때가 있다.
- 쿠버네티스의 전체적인 아이디어는 그 위에 실행되는 애플리케이션으로부터 실제 인프라스트럭처를 숨기는 것에 있기에 파드가 어떤 노드에 스케줄링돼야 하는지 구체적으로 지정하고 싶지는 않을 것이다.
- 그래서 정확한 노드를 지정하는 대신 필요한 노드 요구 사항을 기술하고 쿠버네티스가 요구 사항을 만족하는 노드를 선택하도록 한다.
3.5.1 워커 노드 분류에 레이블 사용
- 모든 쿠버네티스 오브젝트에 레이블을 부착할 수 있다.
- 일반적으로 팀에서 새 노드를 클러스터에 추가할 때, 노드가 제공하는 하드웨어나 파드를 스케줄링할 때 유용하게 사용할 수 있는 기타 사항을 레이블로 지정해 노드를 분류한다.
$ kubectl label node gke-kubia-85f6-node-0rrx gpu=true
# gke-kubia-85f6-node-0rrx 노드에 gpu=true라는 레이블을 붙임
$ kubectl get nodes -l gpu=true
# gpu=true 레이블을 가진 노드를 나열3.5.2 특정 노드에 파드 스케줄링
3.5.3 하나의 특정 노드로 스케줄링
- 파드는 특정한 노드로 스케줄링하는 것도 가능하다
- 각 노드에는 키를 kubernetes.io/hostname으로 하고 값에는 호스트 이름이 설정된 고유한 레이블이 있기 때문이다.
- 그러나 그 특정 노드가 오프라인 상태인 경우 스케줄링 되지 않을 수 있다.
- 개별 노드로 생각해서는 안된다.
- 레이블 셀렉터를 통해 지정한 특정 기준을 만족하는 노드의 논리적인 그룹을 생각해야한다.
3.6 파드에 어노테이션 달기
- 어노테이션은 키-값 쌍으로 레이블과 거의 비슷하지만 식별 정보를 갖지 않는다.
- 어노테이션은 더 많은 정보를 보유할 수 있다.
- 이는 주로 tools에서 사용된다.
- 쿠버네티스에 새로운 기능을 추가할 때, 파드나 다른 API 오브젝트에 설명을 추가할 때 어노테이션이 유용하게 사용된다.
3.6.1 오브젝트의 어노테이션 조회
- kubectl describe 명령을 이용하거나 YAML 전체 내용을 요청해야 한다.
- 어노테이션에는 상대적으로 큰 데이터를 넣을 수 있다. JSON 사용도 가능하다.
3.6.2 어노테이션 추가 및 수정
$ kubectl annotate pod kubia-manual mycompony.com/someannotation="foo bar"
$ kubectl describe pod kubia-manual # 추가한 어노테이션 확인3.7 네임스페이스를 사용한 리소스 그룹화
- 오브젝트를 겹치지 않는 그룹으로 분할하고자 할 때는 오브젝트를 네임스페이스로 그룹화한다.
- 이는 프로세스를 격리하는데 사용하는 리눅스 네임스페이스가 아니고, 쿠버네티스 네임스페이스는 오브젝트 이름의 범위를 제공한다.
- 같은 리소스 이름을 다른 네임스페이스에 걸쳐 여러 번 사용할 수 있게 해준다.
3.7.1 네임스페이스의 필요성
- 여러 네임스페이스를 사용하면 많은 구성 요소를 가진 복잡한 시스템을 좀 더 작은 개별 그룹으로 분리할 수 있다.
- 또한 multi-tenant 환경처럼 리소스를 분리하는 데 사용된다.
- 리소스를 프로덕션, 개발, QA 환경, 혹은 원하는 방법으로 나누어 사용할 수 있다.
- 리소스 이름은 네임스페이스 안에서만 고유하면 된다.
3.7.2 다른 네임 스페이스와 파드 살펴보기
$ kubectl get ns
# 모든 네임스페이스 확인
$ kubectl get po --namespace kube-system
# kube-system 네임스페이스에 속해 있는 파드를 확인
# --namespace 대신 -n 옵션 사용 가능3.7.3 네임스페이스 생성
- yaml으로 생성
- kubectl create namespace 명령으로 생성
3.7.4 다른 네임스페이스의 오브젝트 관리
- 생성한 네임스페이스 안에 리소스를 만들기 위해서는 metadata 섹션에 namespace: custom -namespace 항목을 넣거나 kubectl create 명령을 사용할 때 네임스페이스를 지정한다.
$ kubectl create -f kubia-manual.yaml -n custom-namespace- 이제 동일한 이름을 가진 두 파드가 있다. 하나는 default 네임스페이스에 있고 나머지는 custom-namespace에 있다.
3.7.5 네임스페이스가 제공하는 격리 이해
- 네임스페이스를 사용하면 오브젝트를 별도 그룹으로 분리해 특정한 네임스페이스 안에 속한 리소스를 대상으로 작업할 수 있게 해주지만, 실행 중인 오브젝트에 대한 격리는 제공하지 않는다.
3.8 파드 중지와 제거
3.8.1 이름으로 파드 제거
$ kubectl delete po kubia-gpu- 파드를 삭제하면 쿠버네티스는 파드 안에 있는 모든 컨테이너를 종료한다.
- 쿠버네티스는 SIGTERM 신호를 프로세스에 보내고 지정된 시간 동안 기다린다. 시간 내에 종료되지 않으면 SIGKILL 신호를 통해 종료한다.
3.8.2 레이블 셀렉터를 이용한 파드 삭제
$ kubectl delete po -l creation_method=manual3.8.3 네임스페이스를 삭제한 파드 제거
$ kubectl delete ns custom-namespace
# 네임스페이스 전체 + 파드 삭제3.8.4 네임스페이스를 유지하면서 네임스페이스 안에 있는 모든 파드 삭제
$ kubectl delete po --all- 만약 레플리케이션컨트롤러에 의해 생성된 파드를 삭제했다면 즉시 새로운 파드를 생성한다. 파드를 삭제하기 위해서는 레플리케이션컨트롤러도 삭제해야 한다.
3.8.5 네임스페이스에서 (거의) 모든 리소스 삭제
- 레플리케이션컨트롤러, 파드, 생성한 모든 서비스 삭제
$ kubectl delete all --all3.9 요약
쿠버네티스의 중심이 되는 빌딩 블록에 대해 알아보았다. 배운 내용은 다음과 같다.
- 특정 컨테이너를 파드로 묶어야 하는지 여부를 결정하는 방법
- 파드는 여러 프로세스를 실행할 수 있으며 컨테이너가 아닌 세계의 물리적 호스트 와 비슷하다.
- YAML 또는 JSON 디스크립터를 작성해 파드를 작성하고 파드 정의와 상태를 확인할 수 있다.
- 레이블과 레이블 셀렉터를 사용해 파드를 조직하고 한 번에 여러 파드에서 작업을 쉽게 수행할 수 있다.
- 노드 레이블과 셀렉터를 사용해 특정 기능을 가진 노드에 파드를 스케줄링할 수 있다.
- 어노테이션을 사용하면 사람 또는 도구, 라이브러리에서 더 큰 데이터를 파드에 부착할 수 있다.
- 네임스페이스는 다른 팀들이 동일한 클러스터를 별도 클러스터를 사용하는 것처럼 이용할 수 있게 해준다.
- kubectl explain 명령으로 쿠버네티스 리소스 정보를 빠르게 찾을 수 있다.
'🍀 Cloud Architect > Kubernetes' 카테고리의 다른 글
| [Kubernetes in Action] Chapter 2. Understanding containers (0) | 2023.07.09 |
|---|---|
| [Kubernetes in Action] Chapter 1. Introducing Kubernetes (0) | 2023.07.09 |