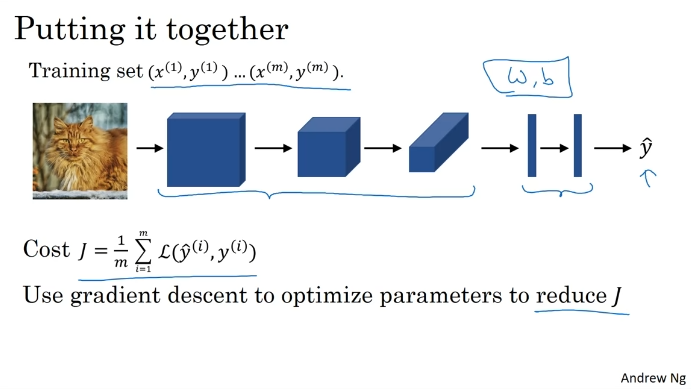
Convolution Neural Networks
Foundations of Convolution Neural Networks
Convolutional Neural Networks
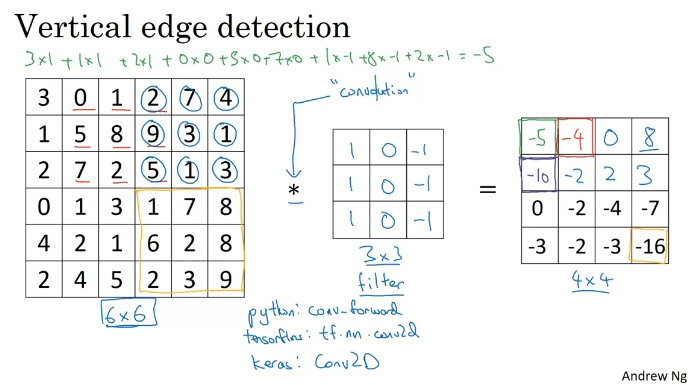
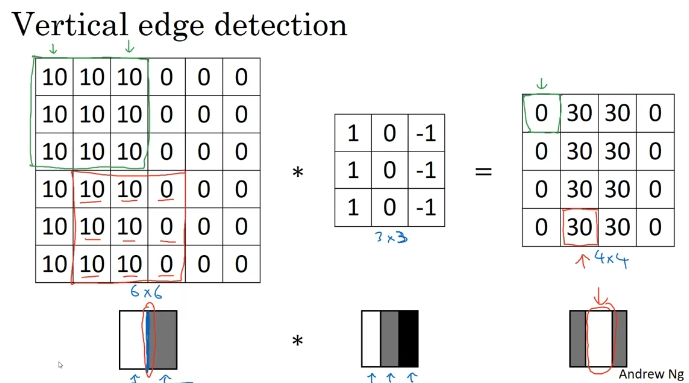
Edge Detection Example
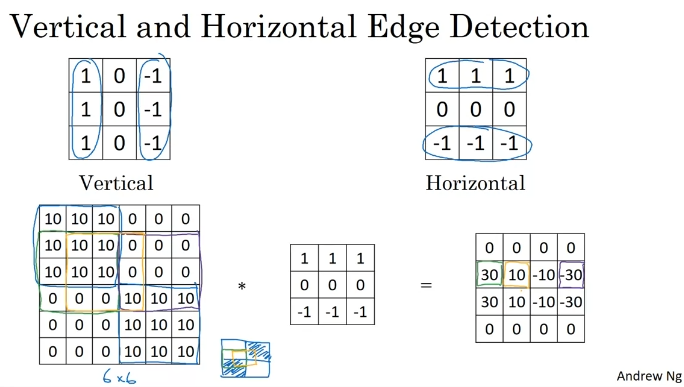
숫자를 1,2,1,0,0,0,-1,-2,-1로 바꾼 sobel filter, 3,10,3,0,0,0,-3,-10,-3로 바꾼 scharr filter를 사용하기도 함.
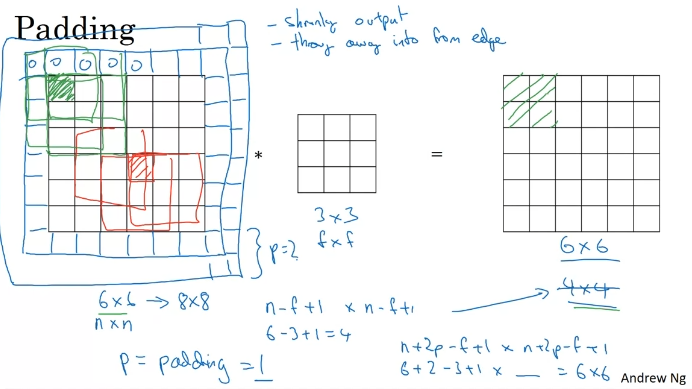
padding - 이미지를 최대한 활용

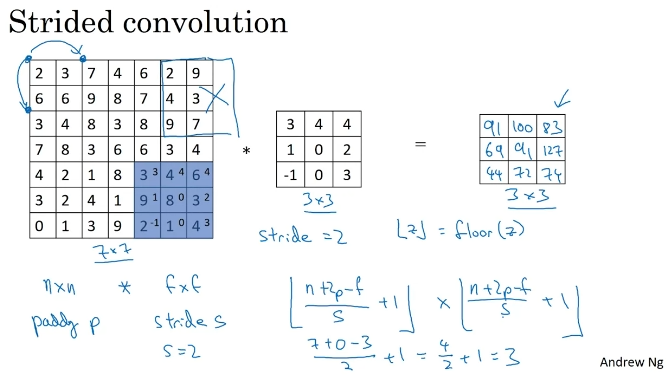
Stried Convolutions - 두 단계씩 점프


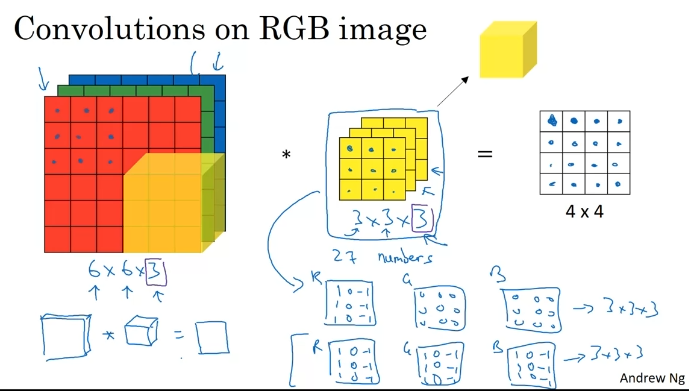
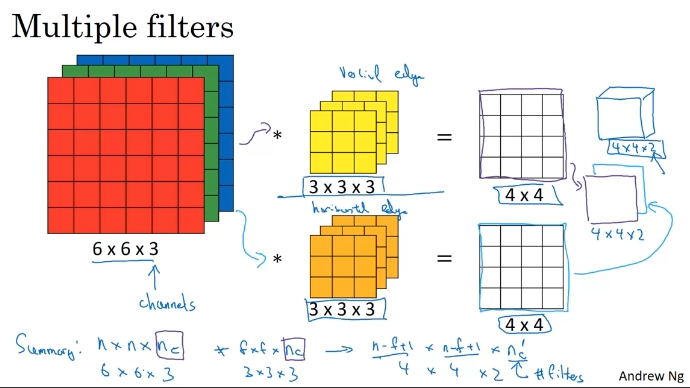
Convolutions Over Volume - 입체형에서의 합성곱
One Layer of a Convolutional Network
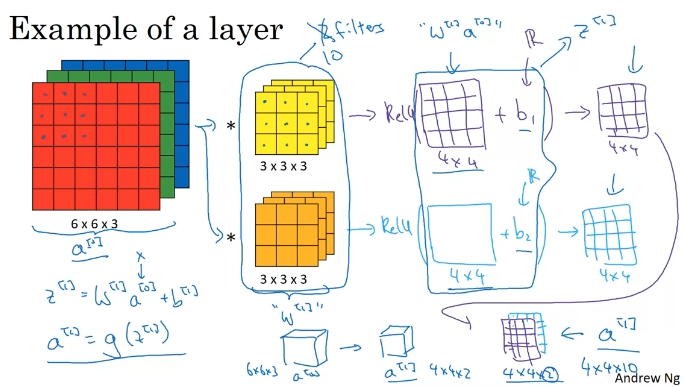

Simple Convolutional Network Example


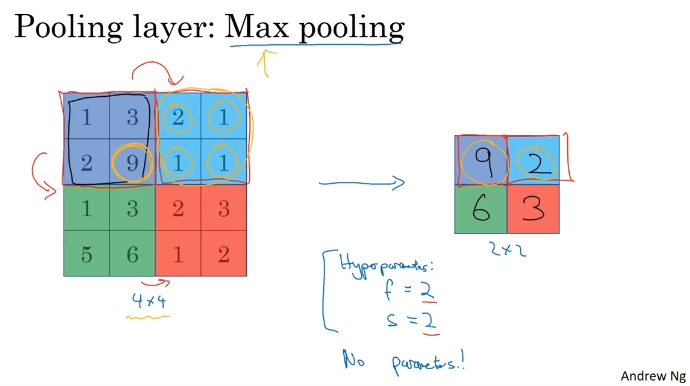
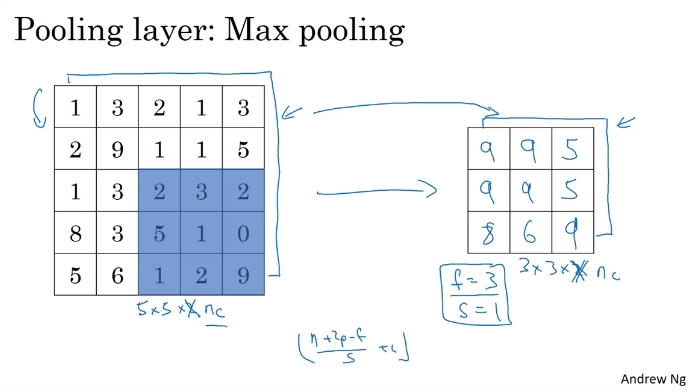
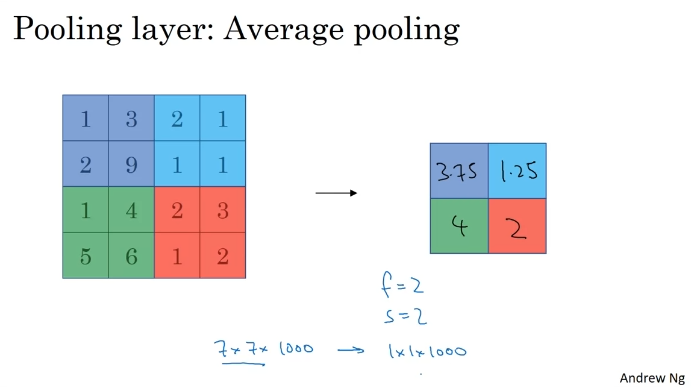
Pooling Layers

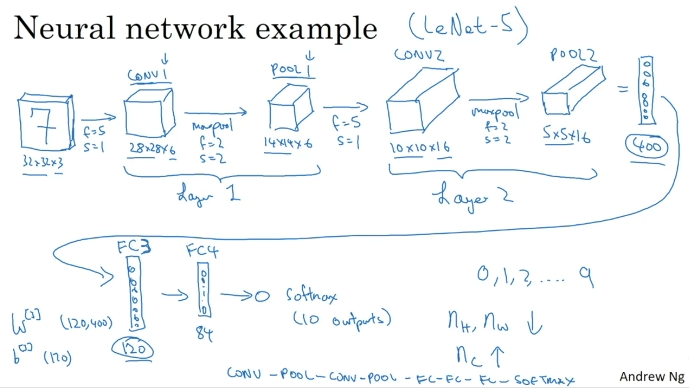
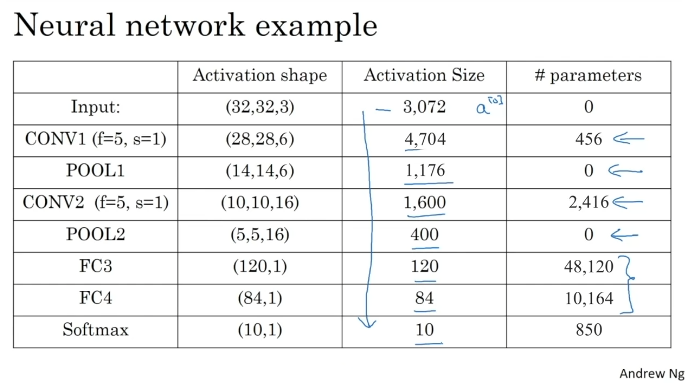
CNN Example
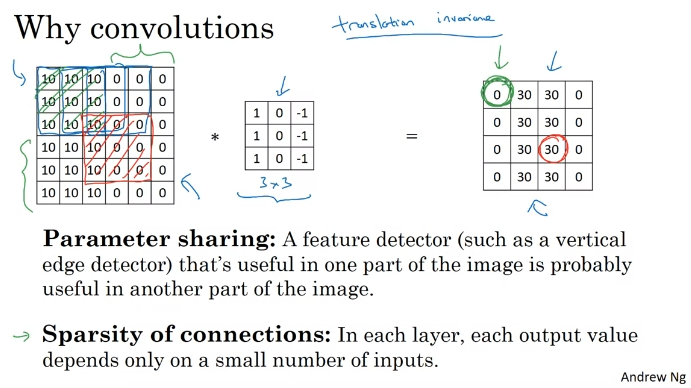
Why convolutions

Deep Convolutional Models: Case Studies
Case Studies
Classic Networks
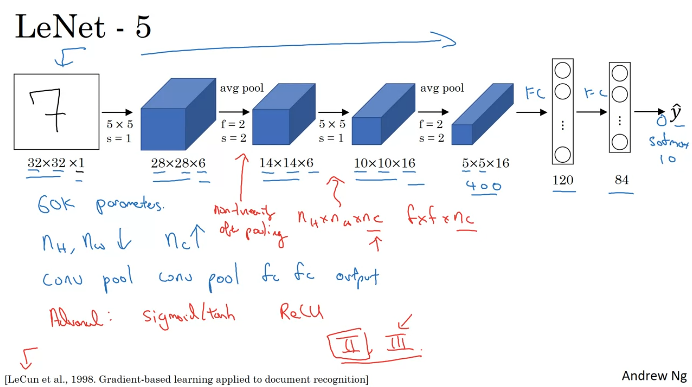
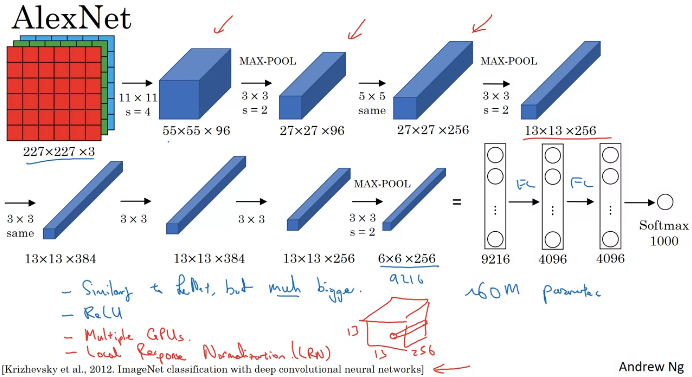
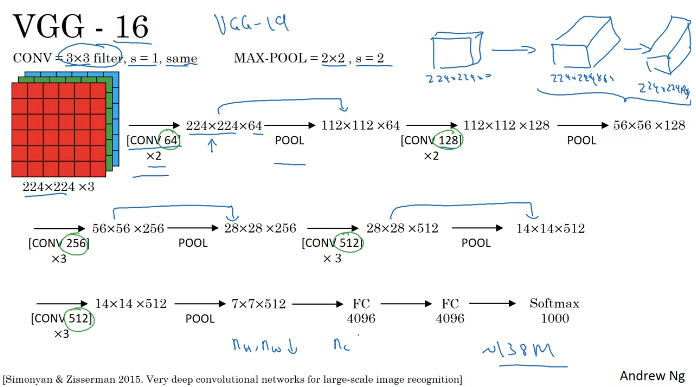
빨간색은 논문을 읽는 사람들을 위한 것. 건너뛰어도 됨.
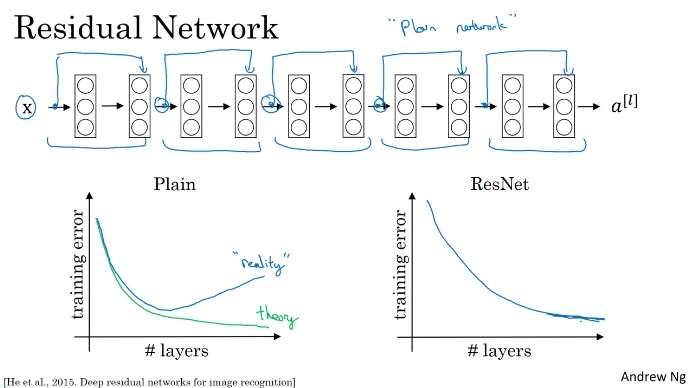
ResNets
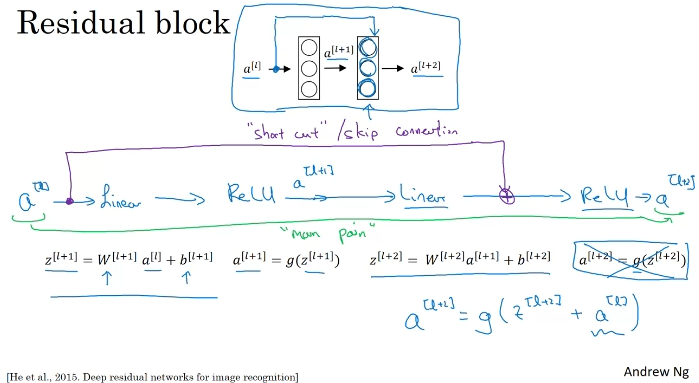
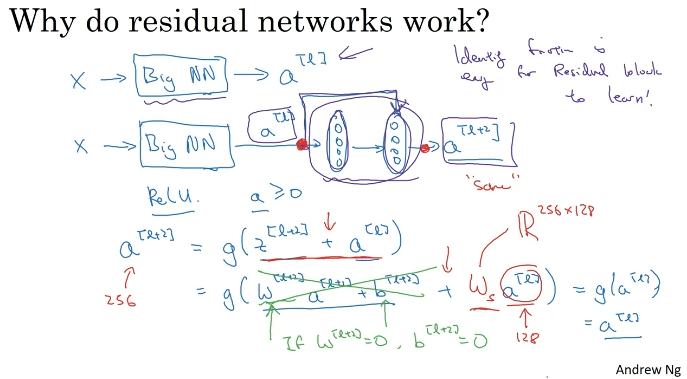
Why ResNets Work?
위 그림에서 두 개의 레이어를 더해도 성능 저하가 일어나지도 않고, 퍼포먼스를 돕는다.
많은 층은 결과물을 오히려 더 나쁘게 만들 수도 있다.
잔류 네트워크가 동작하는 이유는 추가 층이 항등 함수를 쉽게 학습해서 성능을 저하시키지 않고 퍼포먼스를 돕는다.
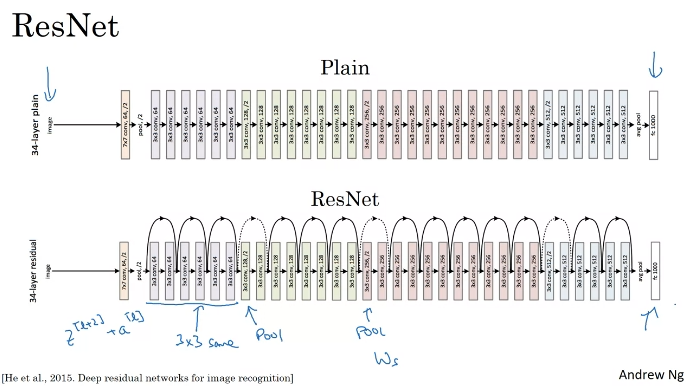
추가 건너띄기 연결을 더하는 것이다.
Networks in Networks and 1x1 convolutions
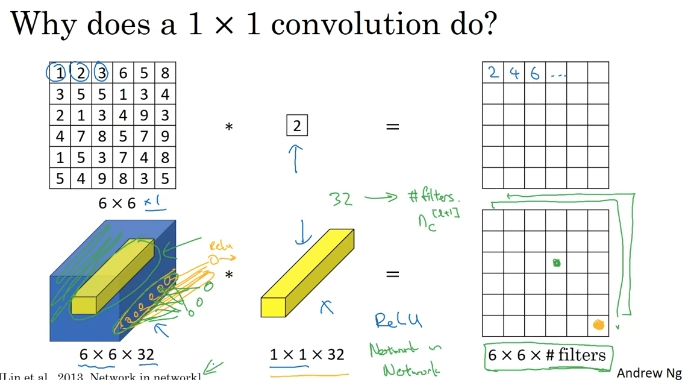
입체형일 때 유용하다. 하나의 뉴런을 가지고 있는 것과 같다. 입력 볼륨에 대해 아주 단순한 계산을 수행할 수 있다.

채널(3번째 곱하는 수)을 축소 (32) 하는 것에 유용하다. 물론 채널 수를 유지(192)할 수도 있다.
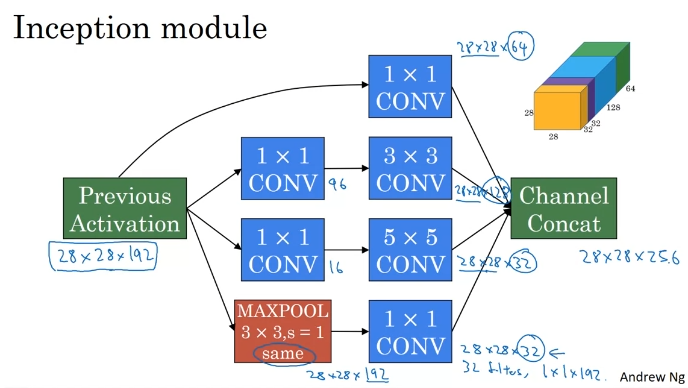
Inception Network Motivation
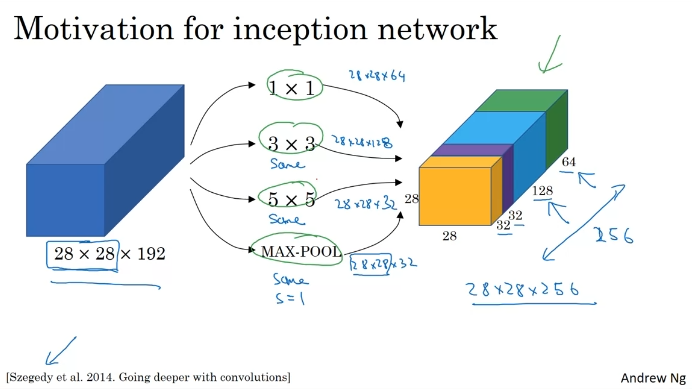
모든 작업을 수행하고 출력을 연결한다.
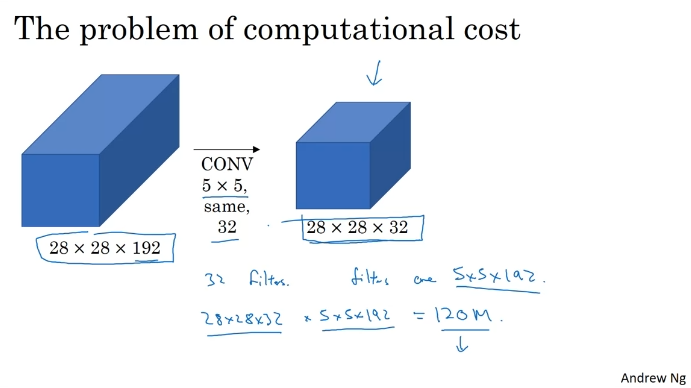
5x5 계산비용. 곱셈을 많이 해야 한다.
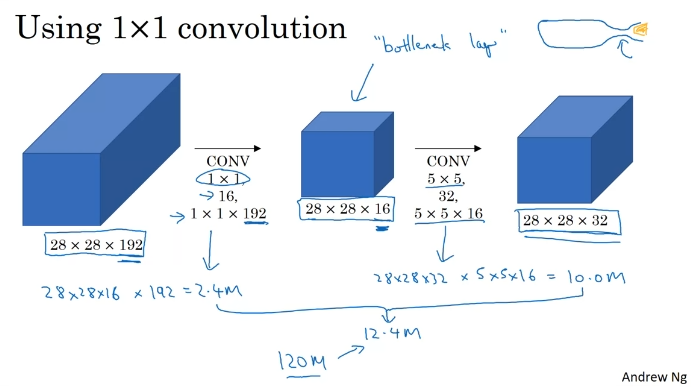
계산 비용(곱셈의 총합)을 많이 축소할 수 있다.
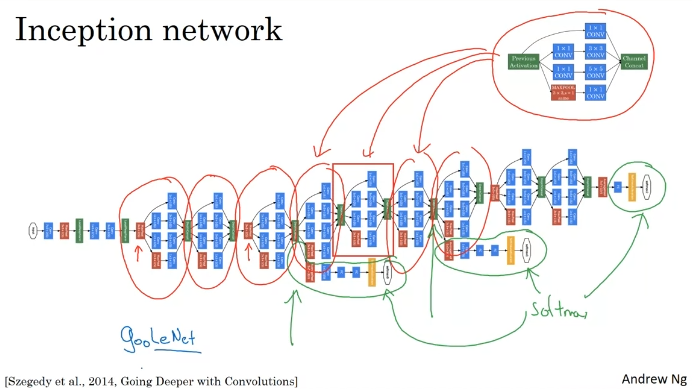
Inception Network
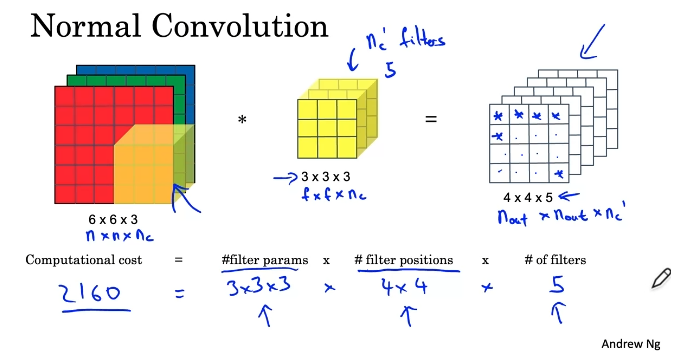
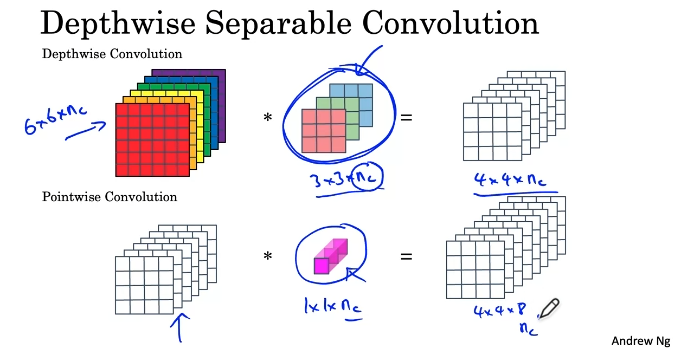
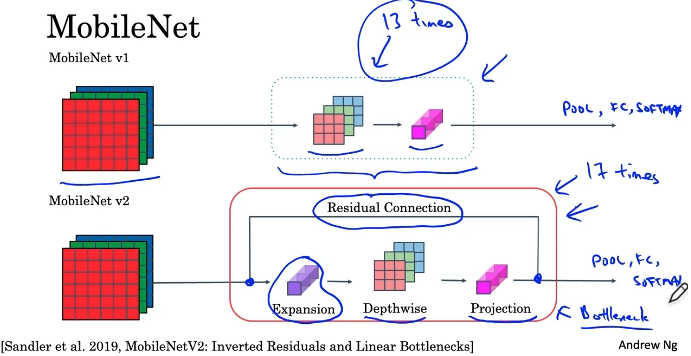
MobileNet
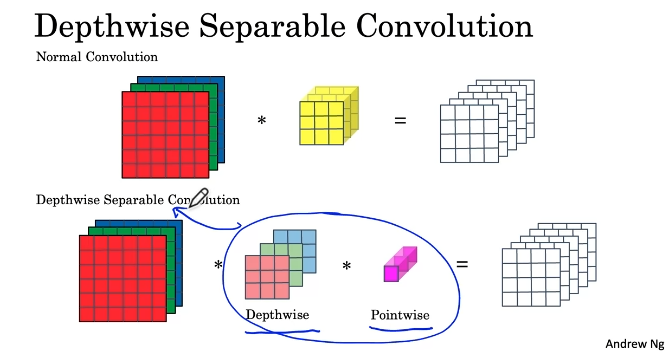

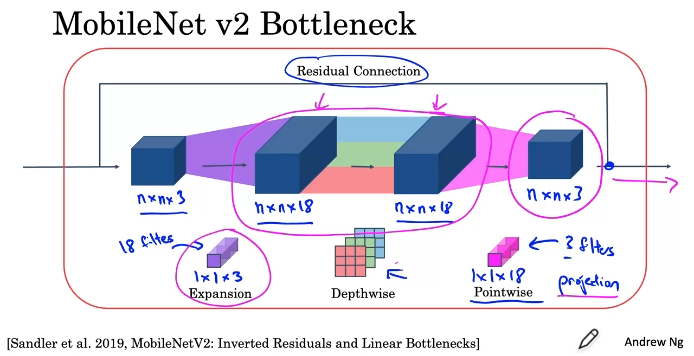
MobileNet Architecture
EffectiveNet
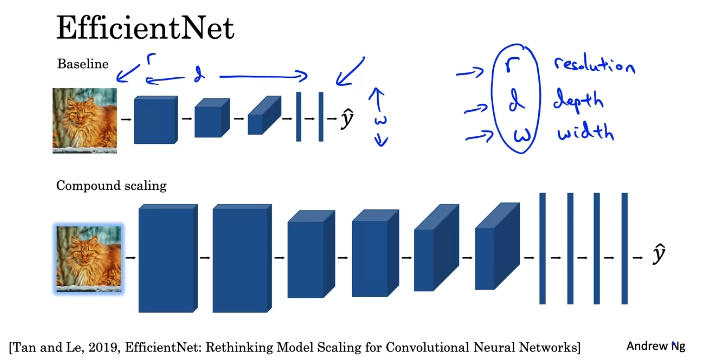
신경망 확장 또는 축소
Practical Advice for Using ConvNets
Transfer Learning
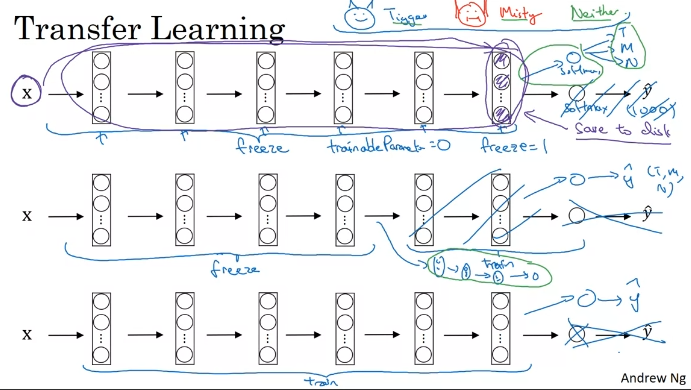
다른 사람의 오픈소스 활용. 전이 학습 항상 실시하기. 인터넷의 다른 학습 세트 활용.
Data Augmentation
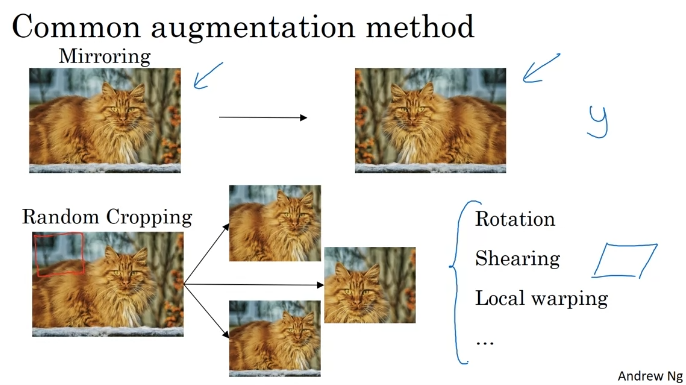
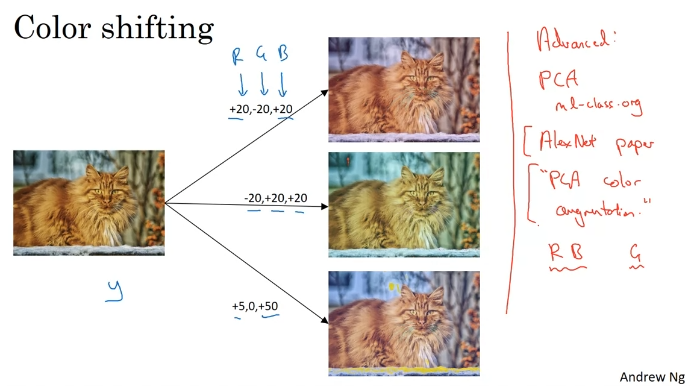
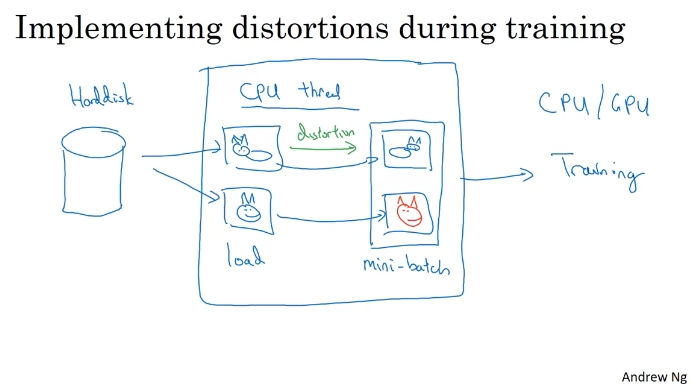
State of Computer Vision

Object Detection
Detection Algorithms
Object Localization
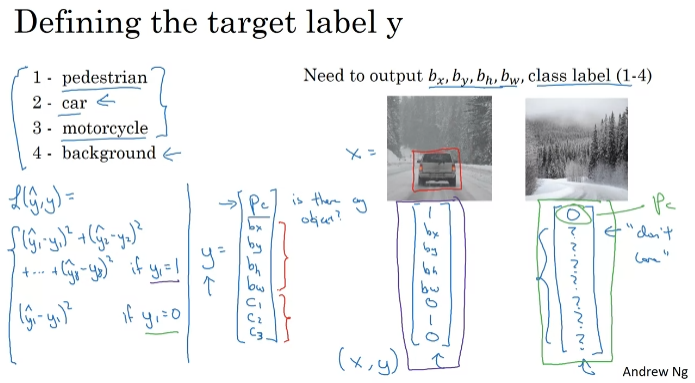
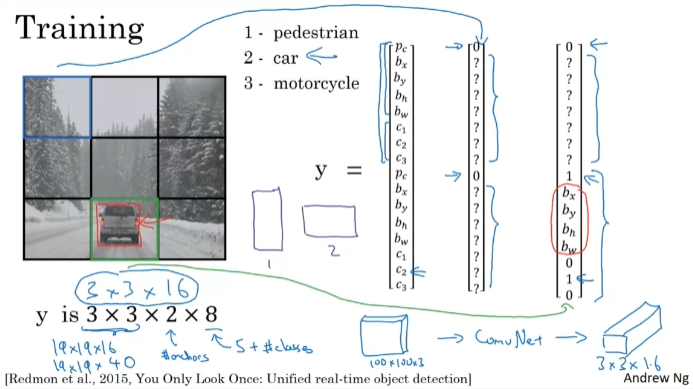
p_c : 객체가 있을 가능성. bx, by, bh, bw가 박스를 결정한다. c1은 보행자, c2는 자동차, c3는 자전거를 의미한다(0,1,0). p_c가 0일 경우 객체가 없는 것이므로 경우 나머지는 신경쓸 필요가 없다.
손실함수를 구할수도 있다.
Lanmark detection
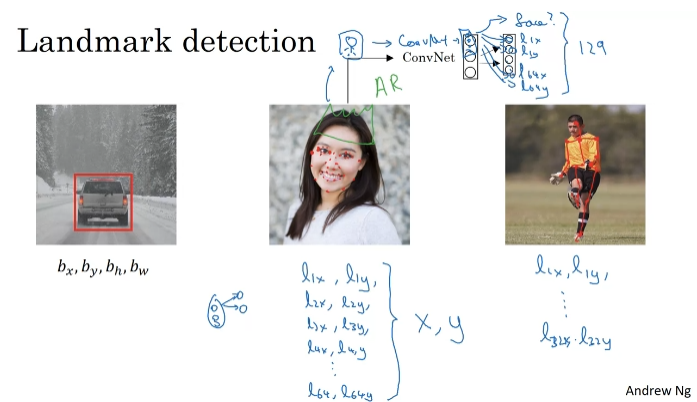
일반적으로, 중요한 점의 x와 y 좌표를 출력할 수 있다.
랜드마크 인식. 가장자리 인식 등. 라벨 훈련 세트가 필요할 것이다.
라벨은 이미지간에 연관성이 있어야 한다.
Object Detection


convnet 학습한 이후 이후 sliding window 감지에서 사용할 수 있다.
computational cost가 든다. 큰 박스를 사용하면 cost는 줄이지만 성능이 줄 수 있다.
신경망이 등장하기 전에는 속도가 많이 느렸다.
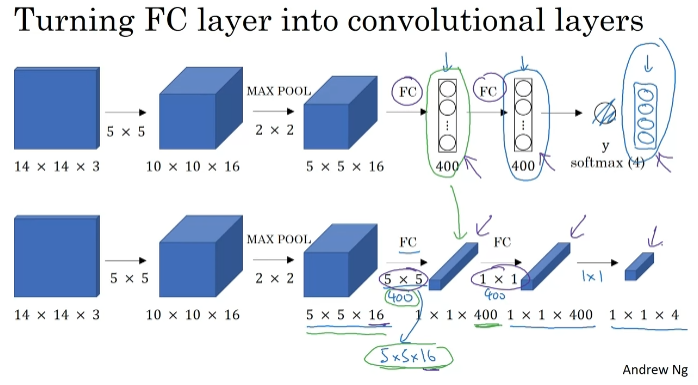
Convolutional Implementation of Sliding Windows
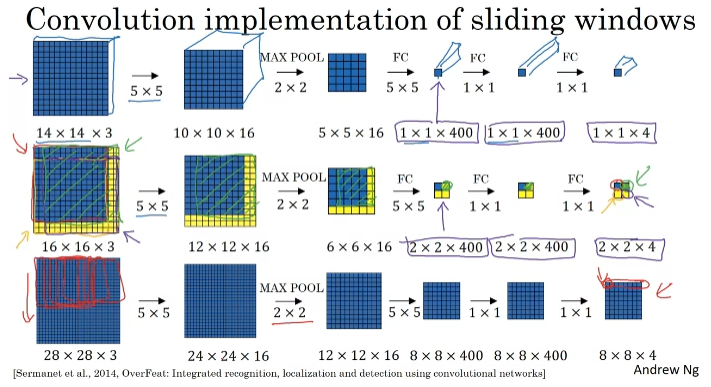
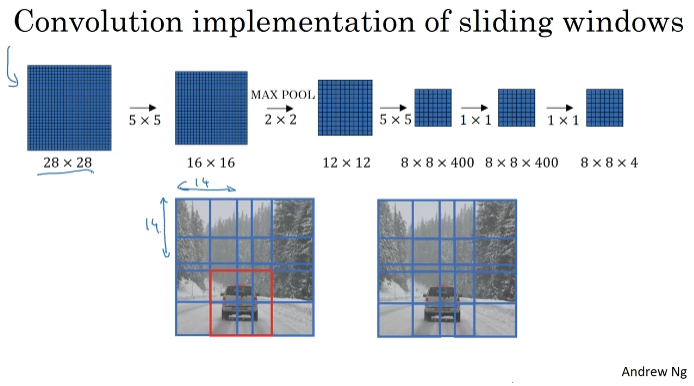
신경망을 이용하여 convolution하게 예측
Bounding Box Predictions
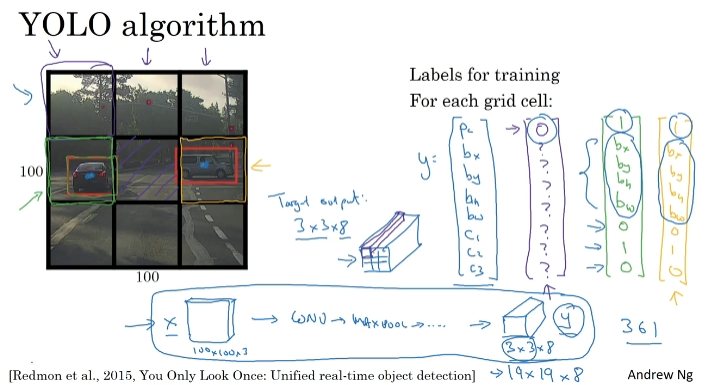
경계박스를 더 정확하게 예측하는 방법. 가장 좋은 방법은 YOLO를 사용하는 것이다.
흥미로운 박스만 신경쓴다. 격자판 안에서 정확한 경계 상자를 얻어낼 수 있다. 중앙 점을 신경씀.
1) 이미지 인식 알고리즘과 비슷하다. , 2)컨볼루션 구현이라 빠르게 실행된다.
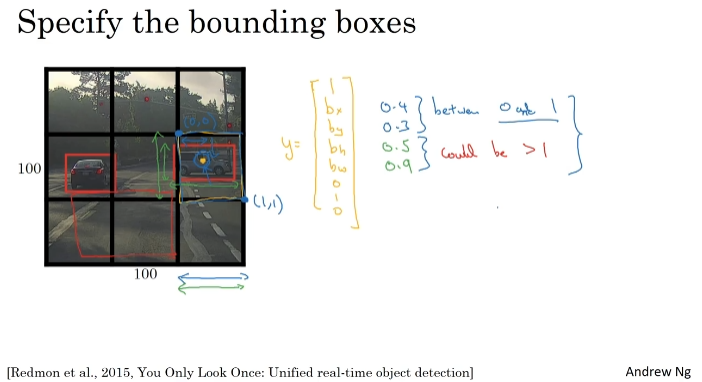
bx, by, bh, bw를 어떻게 바운딩할까? 격자판의 왼쪽 위는 (0,0), 오른쪽 아래는 (1,1)이다. 비율로 결정한다.
Intersection Over Union

IoU. 합집합에 대한 교집합을 계산한다. 교차점의 크기를 계산한다. 판별기준으로 0.5가 관습적으로 사용된다.
Non-max Suppression

각 객체에 대해 여러 탐지가 일어날 수도 있다. Pc를 감지될 가능성이라 한다. 확률이 낮은 박스를 non-max 억제한다. 출력 객체 당 한 번씩 실행한다.

낮은 확률 출력 박스를 삭제한다.
Anchor Boxes
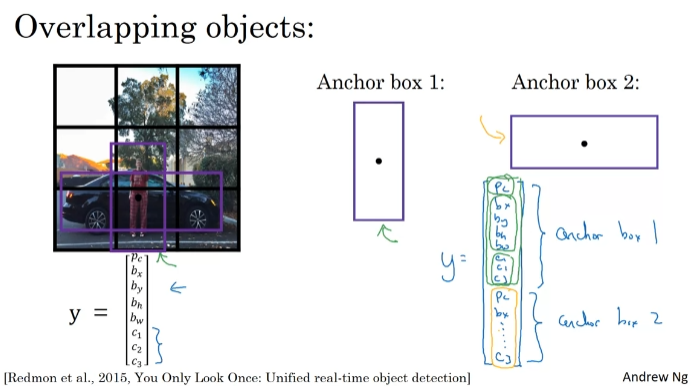

객체 감지 문제 중 하나 = 각 격자판 셀이 하나의 개체만 감지할 수 있음
격자판 셀이 여러 객체를 탐지하려면? Anchor Box 사용
k-means 알고리즘 사용하여 최적화 해볼수도.
YOLO Algorithm

Region Proposals(Optional)


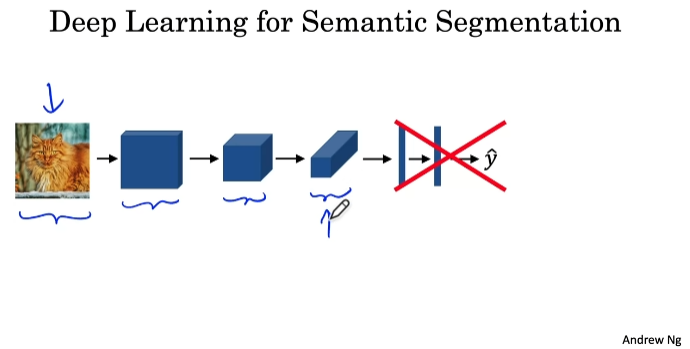
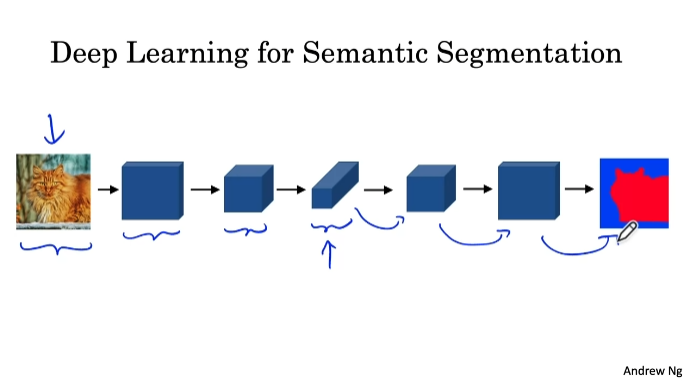
Semantic Segmentation with U-Net

감지된 객체의 주위에 면밀한 윤곽선을 그려서 개체에 속하는 픽셀과 그렇지 않은 픽셀을 정확하게 파악하는 것
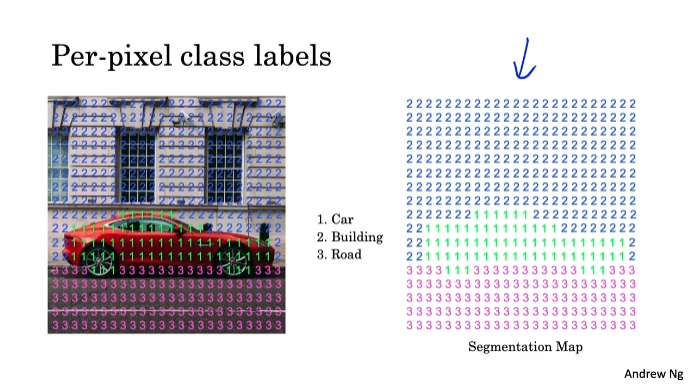
픽셀을 적절히 라벨링하는 것이 핵심이다.
Transpose Convolutions
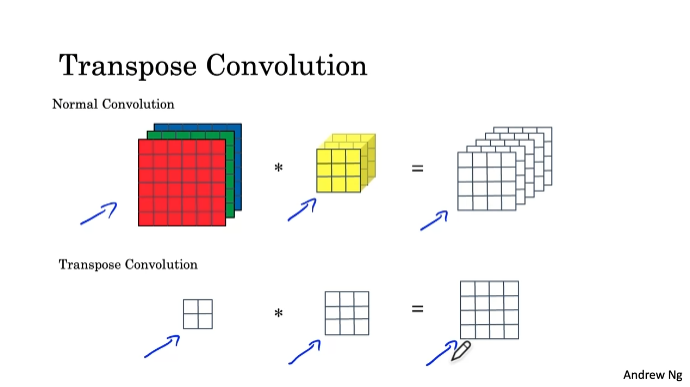
2x2 input을 4x4 output으로 확장
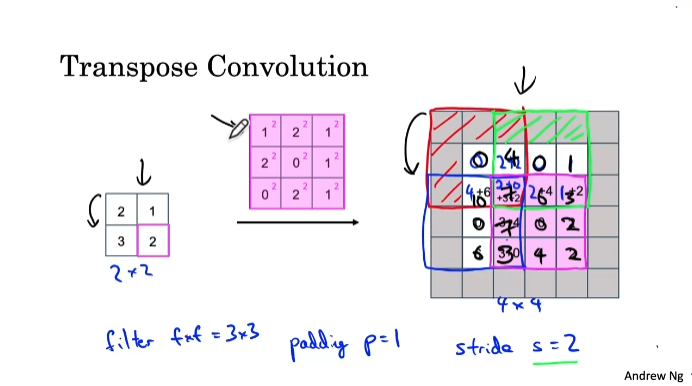
padding, stride 사용
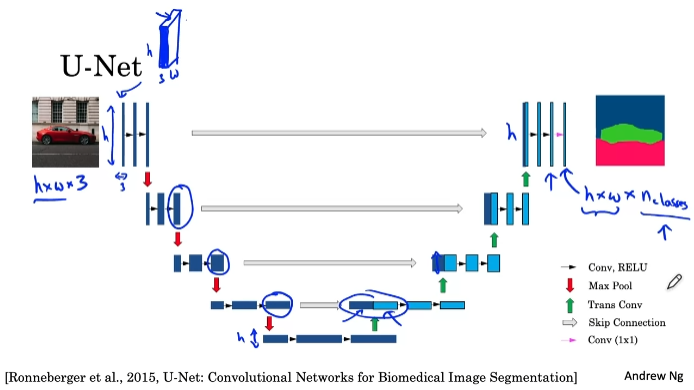
U-Net Architecture Intuition
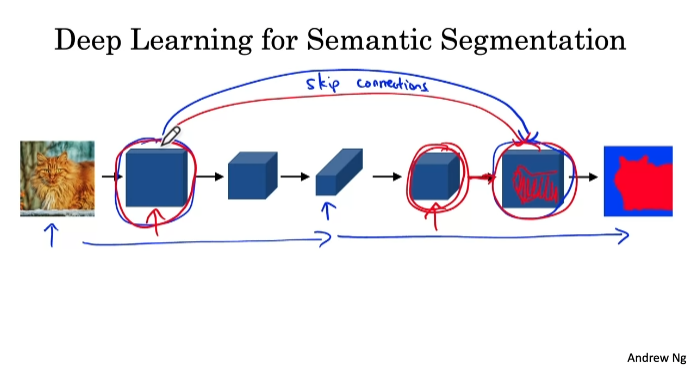
일반 convolution , 전치 convolution 사용
skip connections
U-Net Architecture
Special Applications: Face recognition & Neural Style Transfer
Face Recognition
What is Face Recognition?

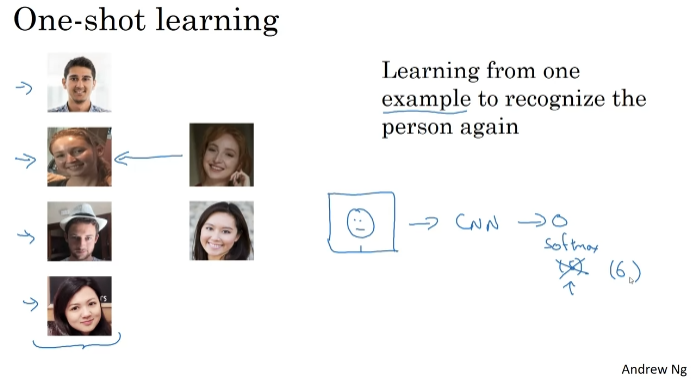
One-shot learning

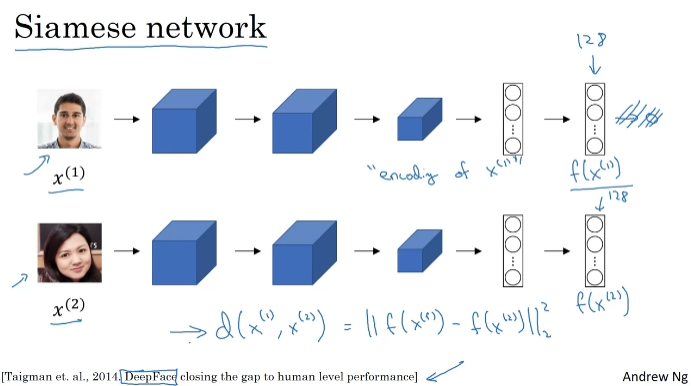
Siamese Network
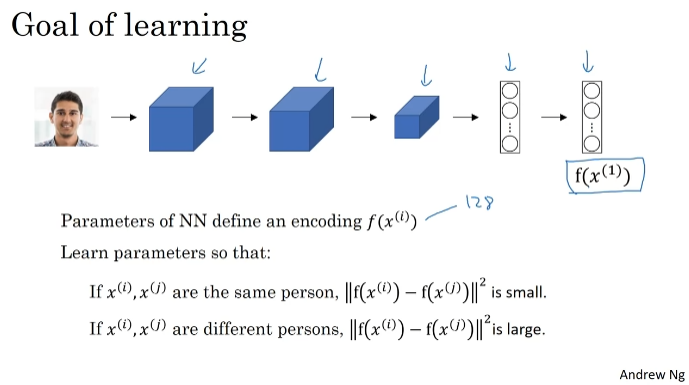
Triplet Loss
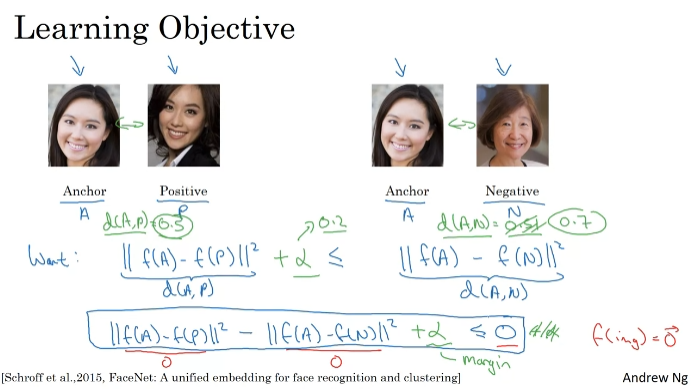



신경망의 parameter를 학습하는 한 가지 방법은 삼중항 손실함수에 경사하강을 정의하고 적용하는 것이다. 이는 얼굴사진에 좋은 인코딩을 제공한다.
이미지 쌍을 비교한다. triple을 mapping한다. (anchor(찾고자하는 사람), positive, negative)
같은 사람일 때 J가 작을 것이고, 다른 사람일 때 J가 클 것이다.
Face Verification and Binary Classification
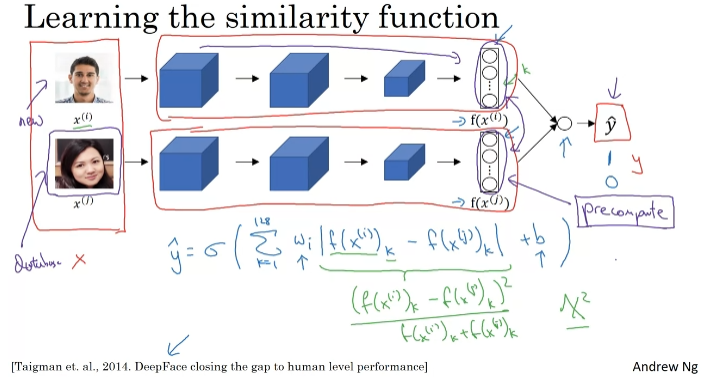

네트워크 쌍을 임베딩한다.
Neural Style Transfer
What is Neural Style Transfer?

What are deep ConvNets learning?
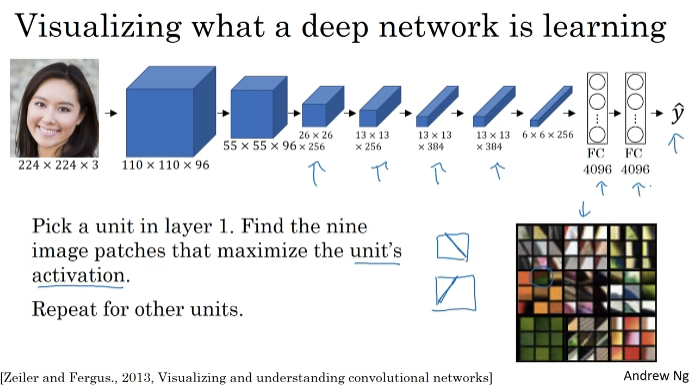

one hidden unit. 선에서부터 복잡한 것까지 구분하게 됨. 9개의 이미지 패치 각각에 대해 뉴런 활성화. 레이어1의 히든 유닛을 훈련시키는 감각을 준다.
Cost Function


Contenct Cost Function

Style Cost Function
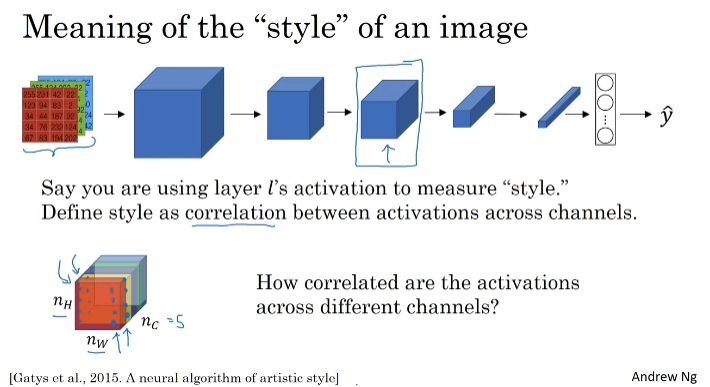

채널 간의 상관관계. 얼마나 자주 같이 발생하는지?


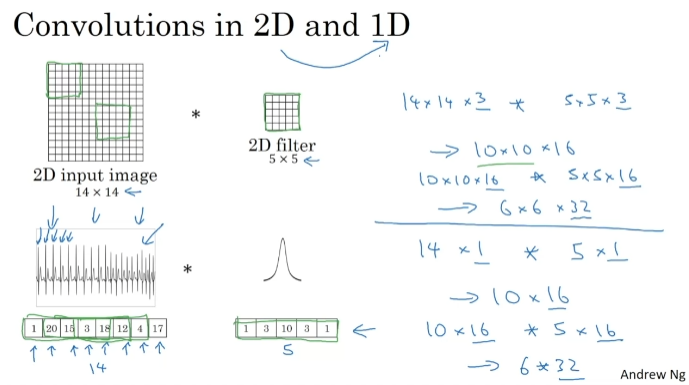
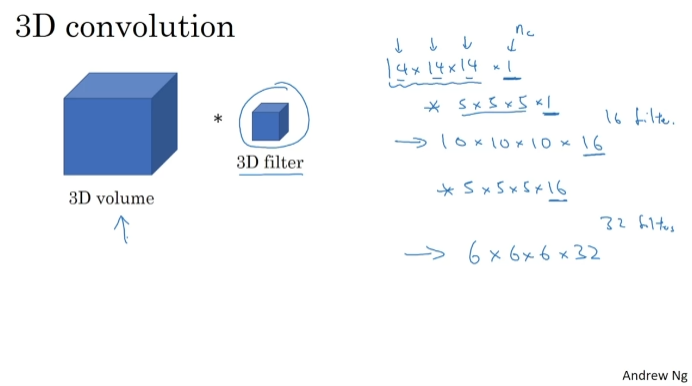
1D and 3D Generalizations