Structuring Machine Learning Projects
Coursera Deep Learning 강의를 정리한 내용입니다.
ML Strategy 1
Introduction to ML Strategy

90% 정확도를 가진 모델을 더 개선하고 싶다
딥러닝 시스템 개선
하지만 6개월 동안 한 시스템 개선이 소용없을 수 없다.
여러 전략을 알고 잘 선택해야 한다.
Orthogonalization.
어떤 효과를 얻기 위해 어떤 것을 튜닝할 것인지에 대한 절차를 아는 것이 중요하다.
직교화의 예시로는, 티비나 자동차의 각 손잡이가 하나의 역할을 수행하도록 하는 것이다.
Chain of assumptions in ML
다음 네 가지가 잘 유지되도록 해야 한다.
- Fit training set well on cost funciton (= human level performance)
- Fit dev set well on cost function
- Fit test set well on cost function
- Performs well in real world
Setting Up your Goal
정밀도(Precision)와 재현율(Recall)을 보기
- recall is, of all the images that really are cats
두 수치를 결합한(평균) F1 score 수치를 더 많이 사용함.
Accuracy + Running time = Cost(종합평가수치)를 사용할 수도 있다.
데이터세트를 분류하기 (dev/test sets)
무작위로 섞인 데이터를 개발과 시험 세트에 반영하는 것을 추천한다.
개발과 시험 세트는 같은 분포에 존재해야 한다.
= Choose a dev set and test set to reflect data you expect to get in the future and consider important to do well on.
Size of Dev and Test Sets
- 머신러닝 초기 (데이터세트 크기가 크지 않을 때)
- 70% Train 30% Test
- 60% Train 20% Dev 20% Test
- 최근 (빅데이터)
- 98% Train 1% Dev 1% Test
테스트 세트가 10000개 정도면 충분하기 때문
When to Change Dev/Test sets and Metrics?
목표를 변경하는 방법
고양이 사진을 조금 더 잘 분류하는데 포르노 사진이 많이 나온다면(분류하지 못한다면) 좋은 알고리즘이라고 할 수 없다.
이럴 때 포르노 사진에 더 큰 가중치를 부여해 오류값이 올라가도록 한다.
이전 오류 지표가 불만족스러운 경우 유지하지 말고 새로운 지표 정의를 시도하면 좋다.

- Orthogonalization for cat pictures: anti-porn
- So far we've only discussed how to define a metric to evaluate classifiers
- Worry separately about how to do well on this ficture
- 비용함수 수정
실제 상황 데이터(프레임이 낮음)에도 잘 대응하기 위해 지표 또는 개발/시험 세트를 바꿔야 한다.
일단 수행하고, 나은 옵션이 나오면 그때 수정하는 것 권장
Comparing to Human-level Performance
Human-level Performance
인간 수준 성능에 도달하기까지는 가파르게 성장한다.
Bayes optimal error: 성능이 이론적인 한계점에 다가갈뿐 도달하지는 않는다. 최상의 오류. x,y 매핑이 일정 정확도를 넘는 방식이다.
- 인간 수준 성능을 넘으면 진행 속도가 더뎌지는 이유
- 인간 수준 성능이 베이즈 최적 오류 지점과 멀리 떨어져 있지 않기 때문이다. 더 발전할 수 있는 부분이 제한적.
- 성능이 인간 수준에 못미치는 경우 여러 도구를 통해 성능 개발이 가능하다. 하지만 이후에는 작업하기 어렵다.
- Humans are quite good at a lot of tasks. So long as ML is worse than humans, you cna:
- Get labeled data from humans.
- Gain insight from manual error analysis: Why did a person get this right?
- Better analysis of bias/variance.
Avoidable Bias

7%를 줄이는 것이 2%를 줄이는 것보다 쉽다.
0.5%를 줄이는 것보다 2%를 줄이는 것이 더 쉽다.
bias/variance avoidance를 적절하게 사용할 수 있다.
Understanding Human-level Performance
Human-level error는 Bayes error를 추정할 수 있게 해준다.
사람마다 다른 Human-level error를 어떻게 결정할까? "목적"에 따라 결정한다.
Bayes error를 추정하기 위한 것이면 가장 낮은 error로 결정(0.5%), 논문을 위함이면 집단에 따라 결정 (1%) 등.

인간과 비슷할수록 발전을 이루기 힘들다.
Human-level error는 Bayes error를 추정할 수 있게 해준다. => bias / vairance를 줄일지 결정 => Human-level performance를 넘기 전까지 잘 작동 => 이후로는 Bayes error 추정값을 구하기 어려워 의사결정에 어려움이 있을 수 있음
Surpassing human-level performance

인간 수준을 넘어서면 발전시킬 수 있는 선택지가 명확하지 않게 됨.
- example
- Online advertising
- Product recommendations
- Logistics(predicting transit time)
- Loan approvals
- Speech recognition
- Computer Vision
- Medical
- ...
충분한 데이터가 있는 경우 딥러닝 시스템이 인간 수준을 넘어서기도 함.
Improving your Model Performance
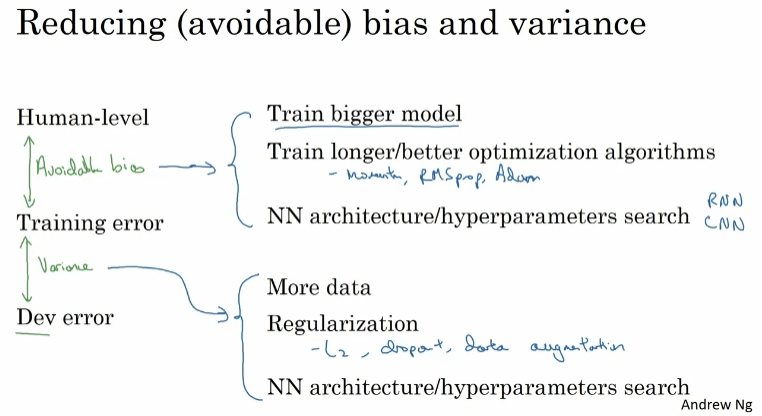
- The two fundamental assumptions of supervised learning
- 1. You can fit the training set pretty well. (~Avoidable bias)
- 2. The training set performance generalizes pretty well to the dev/test set. (~Variance)
ML Strategy 2
Error Analysis
Carrying Out Error Analysis


다양하게 잘못 계산된 예시들을 직접 세면서 비율을 계산하면 우선순위를 정하는 데 도움이 된다.
Cleaning Up Incorrectly Labeled Data
개발 세트 예시가 잘못된 경우이다.
training set에서 잘못 라벨을 붙였을 때? 딥러닝이 랜덤한 에러에 강한 경우 문제가 되지 않는다.
dev/test set에서의 잘못 라벨링된 예시가 걱정되면 error analysis에 추가 열을 넣어 개수를 세는 것을 추천한다.
- 잘못 라벨링된 예시를 줄일지 선택하는 기준 = 아래 에러 비율 살펴보기. 얼마나 큰 에러 비율을 차지하는지 보고 결정하기.
- Overall dev set error
- Errors due incorrect labels
- Errors due to other causes
- Correcting incorrect dev/test set examples
- Apply same process to your dev and test sets to make sure they continue to come from the same distribution
- Consider examining examples your algorithm got right as well as ones it got wrong.
- Train and dev/test data may now come from slightly different distributions.
Build your First System Quickly, then Iterate
- 첫 번째 시스템을 빨리 만들어두고 반복수행하기
- Set up dev/test set and metric
- Build initial system quickly
- Use Bias/Variance analysis & Error Analysis to prioritize next steps.
Mismatched Training and Dev/Test Set
Training and Testing on Different Distributions
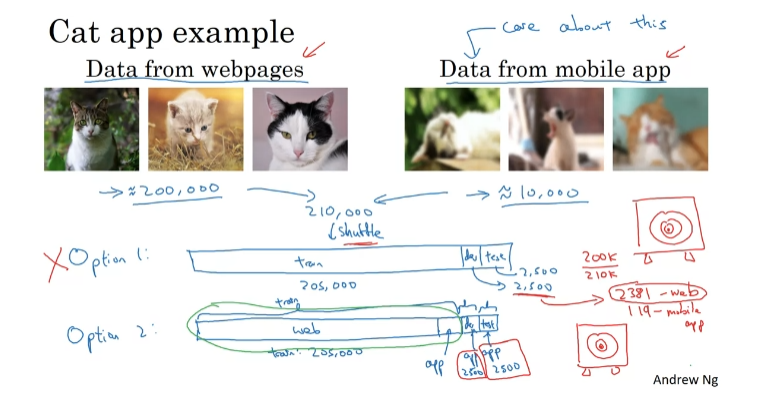
train + dev/test가 서로 분포가 다르다.
Option1: 모두 섞고 테스트한다. 웹 이미지 최적화에 많은 시간을 쏟아야 해서 추천하지는 않는다. 다른 데이터 분포에 맞춰 개발 세트를 최적화하게 하는 것이기 때문.
Option 2: 웹에서 가져온 테스트 데이터를 train에 넣고 분류를 원하는 데이터를 train/dev/test로 나눈다. 이러한 방식을 권장한다.
항상 갖고 있는 데이터를 다 써야 하나? 그렇지만은 않다.
Bias and Variance with Mismatched Data Distributions

오류 분석.

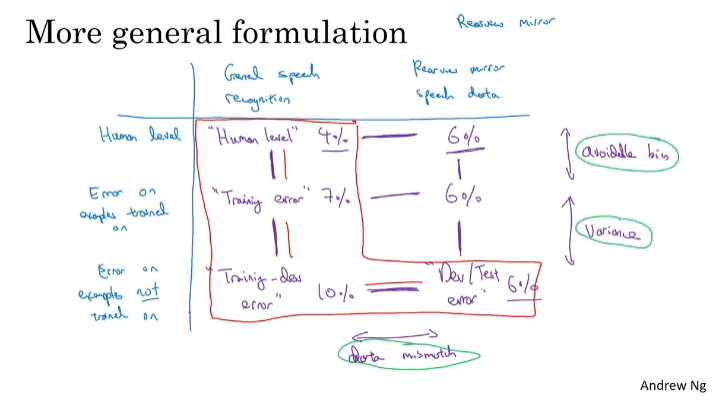
Data Mismatch.
Addressing Data Mismatch
- Addressing data mismatch
- Carry out manual error analysis to try to understand difference between training and dev/test sets
- Make training data more similar; or collect more data similar to dev/test sets
데이터 불일치 문제가 있을 경우 오류 분석을 할 것을 권장한다.
Learning from Multiple Tasks
Transfer Learning
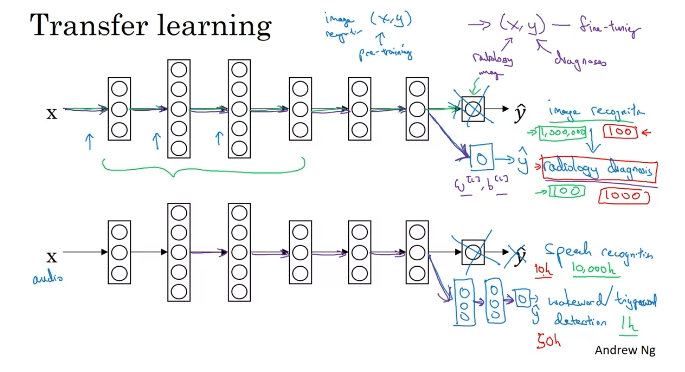
이미지 인식=> 방사선 이미지 인식으로 활용
전이 학습 : 출발 지점에 문제 관련 데이터가 많고 도착 지점에는 관련 데이터가 적은 경우 유용
(방사선 이미지가 적음)
- When transfer learning makes sense
- from A to B
- Task A and B have the same input x.
- You have a lot more data for Task A than Task B.
- Low level features from A could be helpful for learning B.
Multi-task Learning
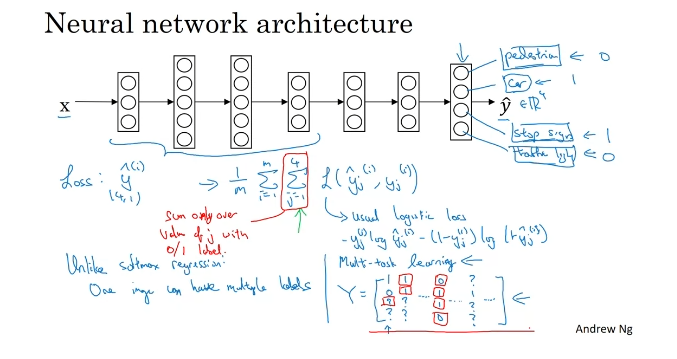
하나의 이미지가 다양한 레이블을 갖는다.
비용 함수를 최소화시키기 위해 신경망을 훈련한다면 이는 Multi-task Learning이다.
한 이미지를 보고 네 개의 문제를 푸는 하나의 신경망을 만드는 것이기 때문이다.
개별 네트워크로 만들 수도 있지만, 신경망의 초반 특성 일부가 다양한 물체들 간에 공유될 수 있는 경우 한 개의 신경망을 훈련시켜 네 개의 일을 할 수 있도록 하는 편이 더 성능이 좋다.
다중작업학습은 일부 이미지에서 일부 객체만 표기해도 잘 구현된다.
일부 라벨을 붙이지 않은 경우는 빼고 라벨이 0이나 1인 j의 값만 더해서 계산한다.
- Whdn multi-task learning makes sense
- Training on a set of tasks that could benefit from having shared lower-level features
- Usually: Amount of data you have for each task is quite similar.
- Can train a big enough neural network to do well on all the tasks.
보통은 전이학습이 다중학습보다 많이 쓰이지만 모두 유용하다.
End-to-end Deep Learning
What is End-to-end Deep Learning?
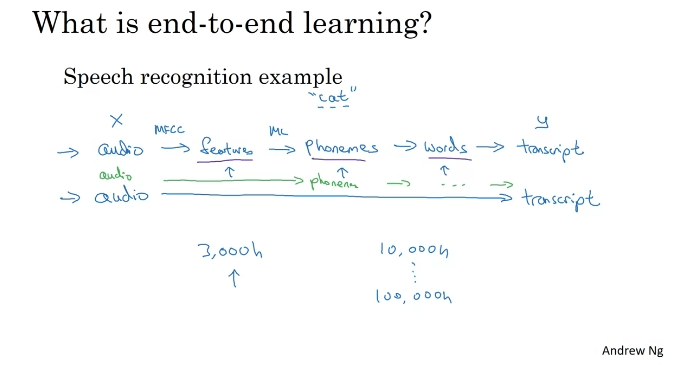
중간 단계를 거치지 않는다.
종단간 딥러닝은 잘 작동하기 위해 많은 양의 데이터가 필요하다.
얼굴 인식의 경우 사진 전체에서 파악하는 것보다 얼굴 주변 이미지를 따고 비교하는 것이 더 성능이 좋다. 하위 작업 데이터가 더 많기 때문이다.
Whether to use End-to-end Deep Learning
- Pros:
- Let the data speak
- Less hand-designing of components needed
- Cons:
- May need large amount of data
- Excludes potentially useful hand-designed components
Key question: Do you sufficient data to learn a function of the complexity needed to map x to y?