Improving Deep Neural Networks: Hyperparameter Tuning, Regularization and Optimization
Coursera Deep Learning 특화 과정의 강의를 듣고 정리하였습니다.
Practical Aspects of Deep Learning
Train/Dev/Test set & Bias/Variance
train set, dev set, test set로 나누어서 계산한다.
빅데이터일수록 train set의 비중이 높아진다.
bias/variance의 개념을 이해한다.
Regularization
L2 정규화
Dropout을 이해한다.
Optimization Problem
Input을 정규화한다.
Vanishing / Exploding Gradients
Weight Initialization for Deep Networks
Gradient Checking
Optimization Algorithms
더 빨리 계산할 수 있게 해주는 Optimization Algorithms
Mini-Batch Gradient Descent
X,Y 대신 X^{T}, Y^{T}로 나누어 계산
예를 들어 500000개의 example을 1000개로 나누어 계산
구현시 vectorization을 도입해서 나누고, 비용 함수를 계산하고, 역전파를 한다. (1 epoch = 1 pass through train set)
batch에서는 1 epoch로 1번의 기울기 하강을 진행하고, mini batch를 사용하면 1 epoch로 5000 단계의 기울기 하강을 진행한다.

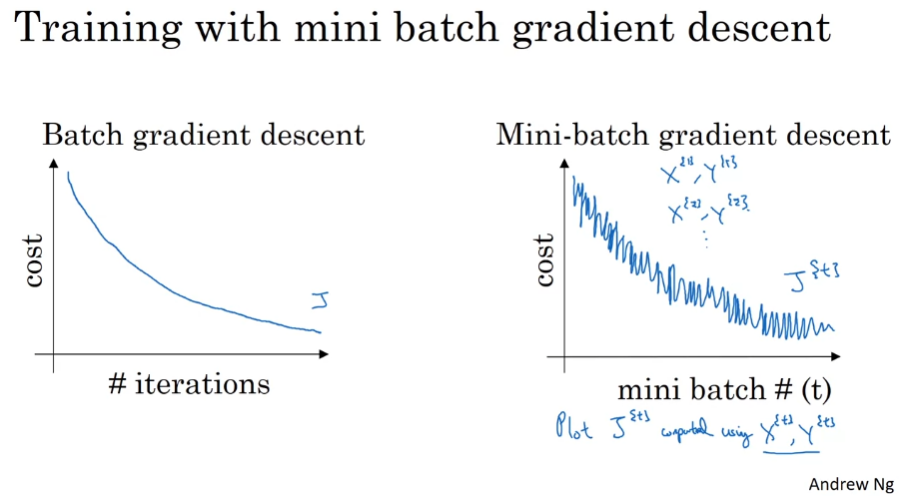
미니배치에서는 비용함수가 항상 감소하지는 않는다. 레이블이 잘못되었거나 복잡할 가능성..
우리는 parameter로 mini-batch의 크기를 골라야 한다.
- minibatch size = m : Batch gradient descent (X{1}, Y{1}) = (X,Y)
- too long per iteration
- minibatch size = 1 : Stochastic gradient descent (Every example is it own mini batch) (확률적)
- you lose almost all your speed up from vectorization
- In practice = 1과 m 사이: Fastest learning
- 아래와 같은 장점 존재
- get a lot of vectorization
- make progress, without needing to wail til you process the entire training set
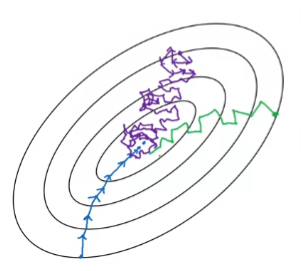
mini-batch size를 고르는 가이드라인
- If small training set (m<=2000) : Use Batch gradient descent
- Typical mini-batch size : 64, 128, 256, 512, ...
- Make sure minibatch (X^{t}, Y^{t}) fit in CPU/GPU memory
Exponentailly Weighted Averages
기울기 하강보다 빠른 최적화 알고리즘을 소개할 것이다.
이러한 알고리즘을 이해하려면 지수 가중 평균 (Exponentailly Weighted Averages)를 이해해야 한다.
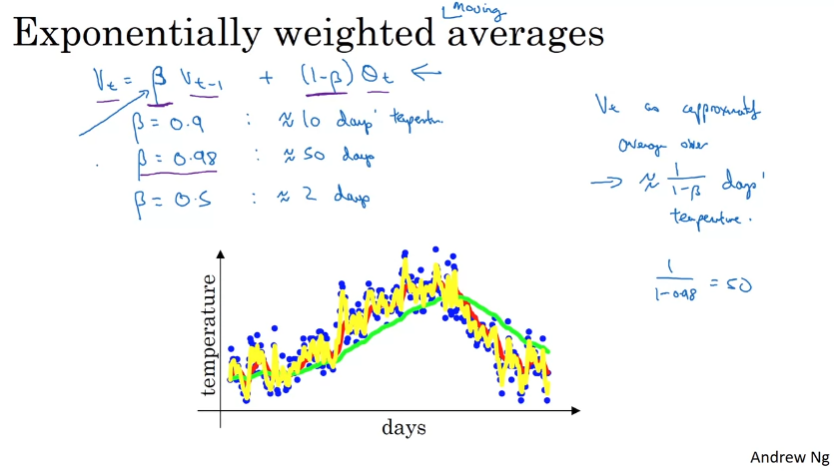
v(t) = Bv(t-1) + (1-B)theta(t) = (1-B)theta(t) + Bv(t-1) = (1-B)theta(t) + B((1-B)theta(t-1) + Bv(t-2)) ...
v_theta라는 한 값만 메모리에 보관하고 계속 업데이트하면 된다.
Gradient descebt with momentum

RMSprop
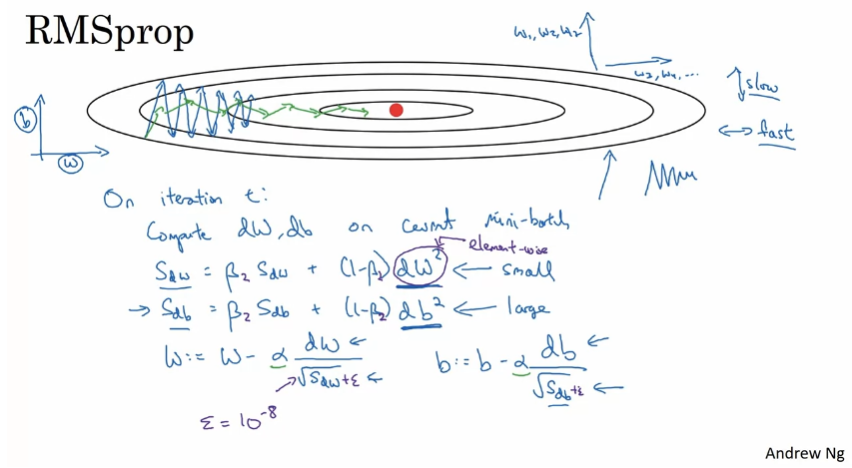
RootMean Squared Prop
미분을 제곱하고, 마지막에 제곱근 적용
sdw가 0이 되어 0으로 나눠지는 것을 방지하기 위해 작은 앱실론을 더한다.
Adam Optimization Algorithm

momentum 경사하강이 잘 동작하여 더 나은 것을 찾기 어려웠다.
새롭게 찾은, momentum과 rms를 합친 것이 adam.

Learning Rate Decay
학습 알고리즘의 속도를 높이는 데 도움이 될 수 있는 것 중 하나는 시간에 따라 학습률을 천천히 줄이는 것이다.

Please note that in the next video, the formula for learning rate decay is:
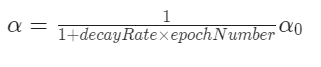
Problem
Hyperparameter Tuning, Batch Normalization and Programming Frameworks
Hyperparameters
중요도에 따라 나열
- 1st
- alpha : learning rate
- 2nd
- Beta : momentum : ~0.9
- number of hidden units
- mini-batch size
- 3rd
- number of layers
- learning rate decay
- 4th
- Beta1, Beta2, epsilon : Adam Optimization Algorithm : 0.9, 0.999, 10^-8
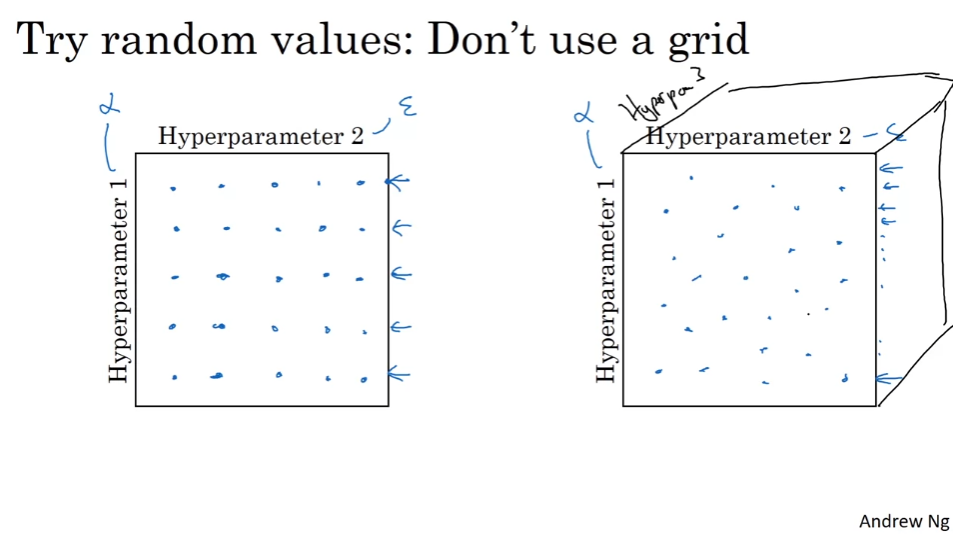
가장 잘 작동하는 parameter 찾기
딥러닝에서는 hyperparamter를 임의로 지정하는 방법을 추천
hyperparamer의 중요도가 영향을 줄 수 있기 때문에
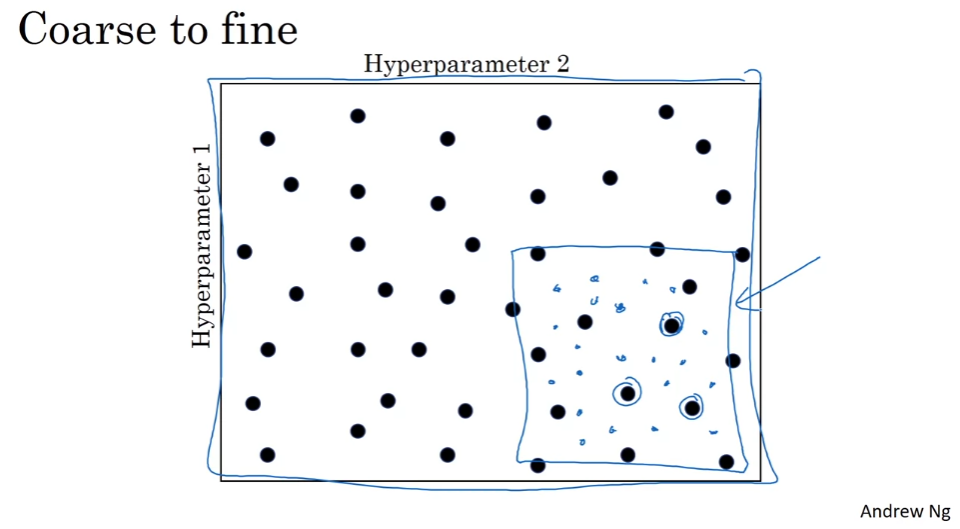
가장 잘 동작하는 parameter. 주변의 parameter도 잘 동작. 조밀하게 sampling
적절한 척도를 설정하기. 로그 스케일 내에서 값을 선정하기.

모델 하나를 테스트하거나 병렬적으로 여러 모델을 테스트할 수 있다. 자원에 따라 선택하기.
Batch Normalization
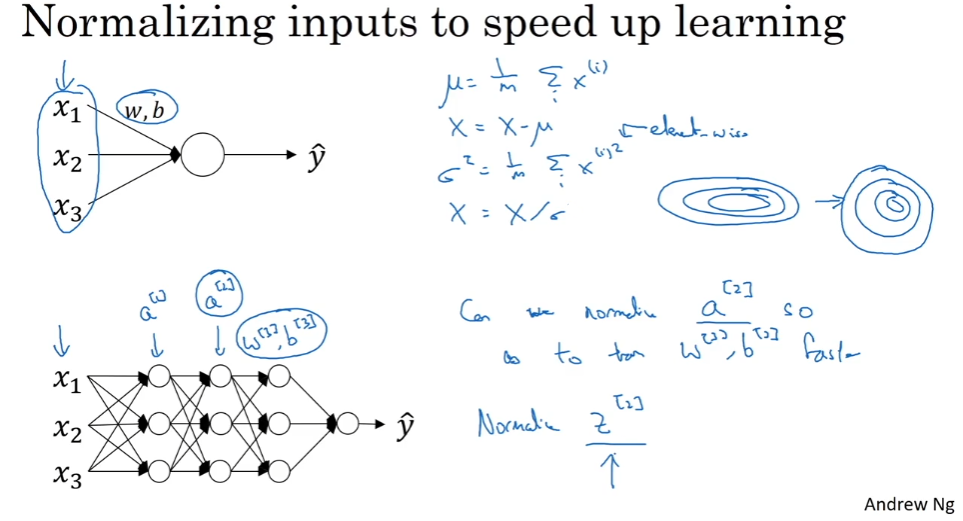
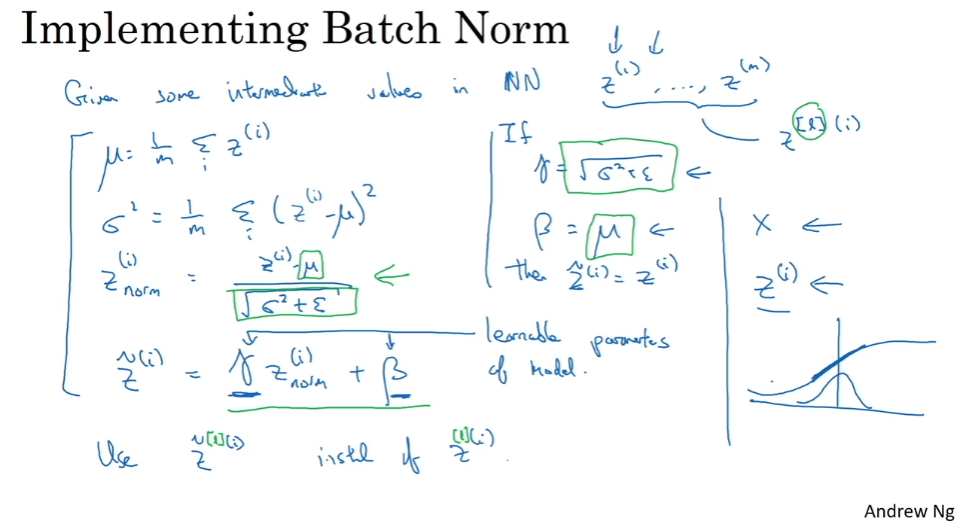
Batch Norm은 학습률을 극적으로 높여준다. 모든 범위를 정규화, x가 비슷한 범위.
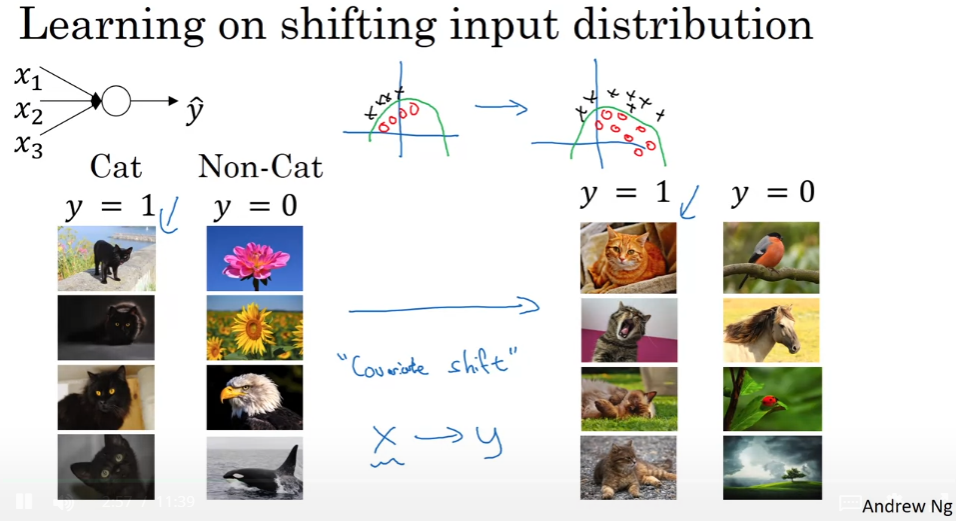
데이터의 범위가 바뀜.
batch norm as regularization
- Each mini-batch is scaled by the mean/variance computed on just that mini-batch
- This adds some noise to the values z^[l} within that minibatch. So similar to dropout, it adds some noise to each hidden layer's activations.
- This has a slight regularization effect.
큰 mini-batch size, noise 줄이고 결과적으로 regularization 효과를 줄임
batch norm은 일반화의 의도를 가지지는 않았지만 의도하지 않은 효과를 냄
batch norm은 일반화로 쓰지 말고 정규화로 쓰기

batch norm은 데이터를 한 번에 하나의 mini-batch로 처리하지만 test time에는 예제를 한 번에 하나씩 처리해야 할 수도 있다
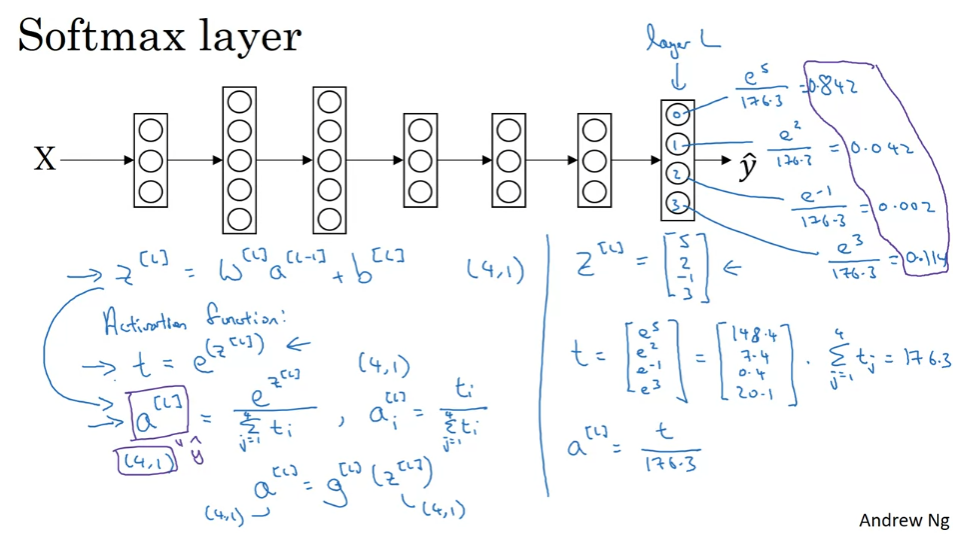
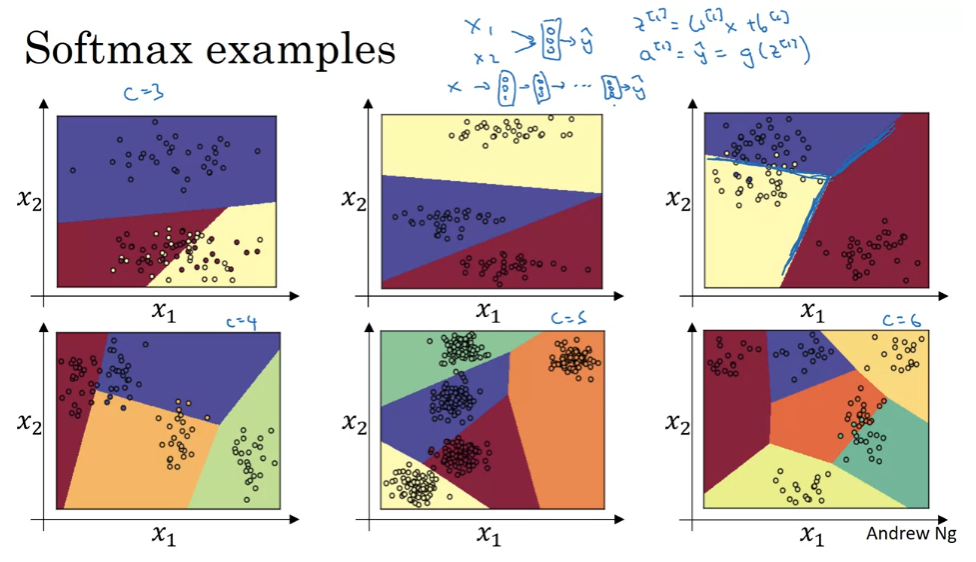
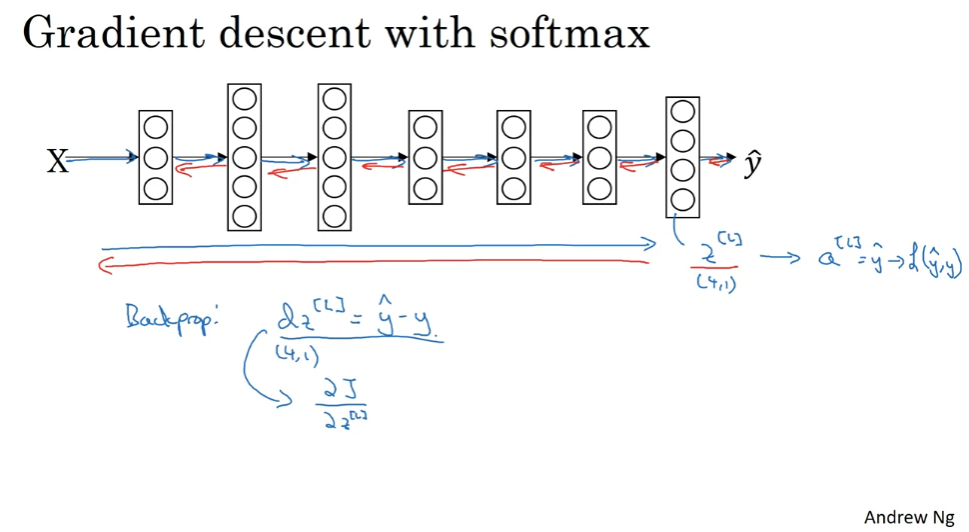
Soft Regression
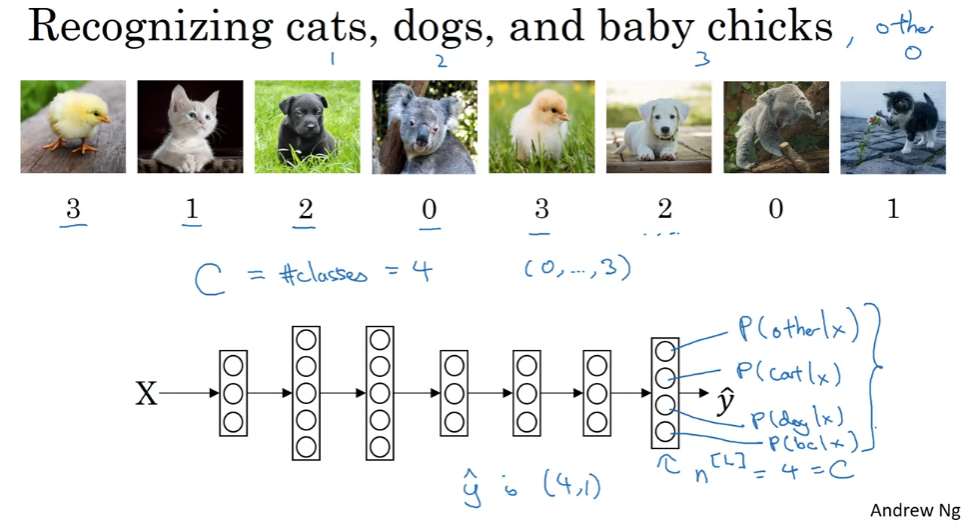
0,1로 구분하는 것 이상. 여러 개를 구분


Deep Learning Frameworks: TenserFlow
tenserflow로 학습시킬 수 있다.